iPAS AI應用規劃師 初級
L11301 機器學習基本原理
出題方向
1
機器學習基礎 & 定義
2
監督式學習原理
3
非監督式學習原理
4
強化學習原理
5
資料 & 特徵於機器學習之角色
6
訓練、驗證、測試概念
7
過擬合 & 欠擬合
8
模型評估基礎概念
#1
★★★★★
機器學習 (ML) 的核心概念是讓電腦系統能夠從資料中學習,而不需要進行明確的
編程。請問下列何者最能體現此概念?
答案解析
機器學習 (ML, Machine Learning) 的
核心在於從資料中學習模式,並利用這些模式來進行預測或決策,而非依賴開發者預先編寫的固定規則。
(A) 透過分析大量歷史郵件(資料),系統學習到垃圾郵件的 模式(例如特定詞彙、寄件者特徵等),並能自動辨識新的垃圾郵件,這正是 機器學習的典型應用。
(B) 依賴固定規則是傳統程式設計的方法,而非機器學習。
(C) 手動分類是人工操作,沒有學習過程。
(D) 關鍵字搜尋是基於預設條件的查找,並非從資料中學習模式。
(A) 透過分析大量歷史郵件(資料),系統學習到垃圾郵件的 模式(例如特定詞彙、寄件者特徵等),並能自動辨識新的垃圾郵件,這正是 機器學習的典型應用。
(B) 依賴固定規則是傳統程式設計的方法,而非機器學習。
(C) 手動分類是人工操作,沒有學習過程。
(D) 關鍵字搜尋是基於預設條件的查找,並非從資料中學習模式。
#2
★★★★
在監督式學習 (Supervised Learning) 中,模型訓練時需要使用哪種類型的資料?
答案解析
監督式學習的核心在於從已知答案的範例中學習。訓練資料必須包含兩部分:
輸入特徵(模型需要分析的資訊)和對應的正確輸出標籤(模型需要學習預測的目標或答案)。模型透過比較自己的預測和
正確標籤之間的差異來進行調整與學習。例如,在房價預測中,輸入特徵是房屋大小、地點等,輸出標籤是實際售價。
(A) 只有輸入特徵不足以讓模型知道學習的目標。
(C) 未標記資料主要用於非監督式學習。
(D) 只有輸出標籤沒有輸入特徵,模型無法學習輸入與輸出的關聯。
(A) 只有輸入特徵不足以讓模型知道學習的目標。
(C) 未標記資料主要用於非監督式學習。
(D) 只有輸出標籤沒有輸入特徵,模型無法學習輸入與輸出的關聯。
#3
★★★★
下列哪種機器學習任務最適合使用非監督式學習 (Unsupervised Learning)?
答案解析
非監督式學習的主要目標是在沒有預先定義標籤的情況下,從資料中找出潛在的結構或模式。常見的應用包括
分群 (Clustering) 和降維 (
Dimensionality Reduction)。
(C) 將客戶根據購買行為自動分群,目的是找出 資料中自然的群組結構,並不需要預先知道客戶屬於哪個群組(沒有標籤),這是典型的非監督式學習中的 分群任務。
(A) 預測下雨(是/否)是分類問題,屬於監督式學習。
(B) 辨識貓或狗也是分類問題,屬於監督式學習。
(D) 預測銷售額是迴歸問題,屬於監督式學習。
(C) 將客戶根據購買行為自動分群,目的是找出 資料中自然的群組結構,並不需要預先知道客戶屬於哪個群組(沒有標籤),這是典型的非監督式學習中的 分群任務。
(A) 預測下雨(是/否)是分類問題,屬於監督式學習。
(B) 辨識貓或狗也是分類問題,屬於監督式學習。
(D) 預測銷售額是迴歸問題,屬於監督式學習。
#4
★★★★★
在機器學習中,用來描述輸入資料的個別可測量屬性或特性,被稱為什麼?
答案解析
在機器學習的術語中,特徵 (Feature) 是指
輸入資料中可以用來進行預測或分類的可測量屬性。例如,在預測房價的任務中,房屋的大小、房間數量、地點、建造年份等都是
特徵。模型會利用這些特徵來學習如何預測目標變數。
(A) 標籤是監督式學習中我們希望預測的輸出值或類別。
(C) 樣本是指資料集中的一個單獨的觀察實例(例如,一筆房屋的資料)。
(D) 模型是從資料中學習到的模式或函數,用來進行預測。
(A) 標籤是監督式學習中我們希望預測的輸出值或類別。
(C) 樣本是指資料集中的一個單獨的觀察實例(例如,一筆房屋的資料)。
(D) 模型是從資料中學習到的模式或函數,用來進行預測。
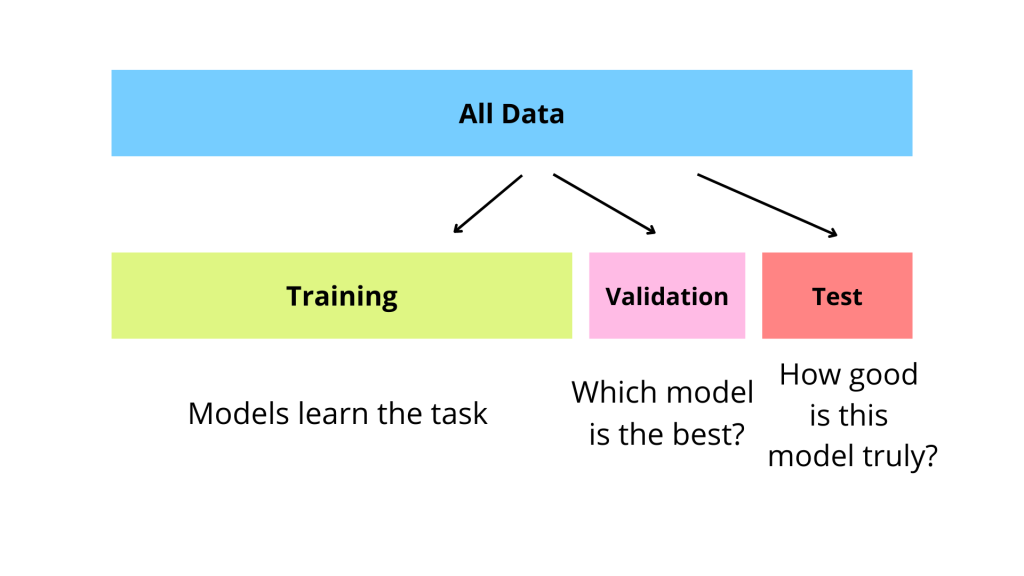
#5
★★★★
在機器學習模型開發過程中,通常會將資料集分成訓練集、驗證集和測試集。請問
驗證集 (Validation Set) 的主要用途是什麼?
答案解析
資料集劃分的目的是:
1. 訓練集 (Training Set): 用於訓練模型,讓模型學習資料中的模式。
2. 驗證集 (Validation Set): 用於在模型訓練過程中 評估不同超參數設定下模型的表現,或者比較不同模型的性能,以便選擇最佳模型和 調整超參數(例如學習率、正則化強度等),避免模型對訓練集過擬合。
3. 測試集 (Test Set): 在模型最終選定後,用來評估模型在從未見過的新資料上的最終性能,即 泛化能力。測試集絕對不能用於訓練或調整模型。
因此,(B) 是驗證集的主要用途。(A) 是訓練集的用途。(C) 是測試集的用途。(D) 與資料集劃分目的無關。
1. 訓練集 (Training Set): 用於訓練模型,讓模型學習資料中的模式。
2. 驗證集 (Validation Set): 用於在模型訓練過程中 評估不同超參數設定下模型的表現,或者比較不同模型的性能,以便選擇最佳模型和 調整超參數(例如學習率、正則化強度等),避免模型對訓練集過擬合。
3. 測試集 (Test Set): 在模型最終選定後,用來評估模型在從未見過的新資料上的最終性能,即 泛化能力。測試集絕對不能用於訓練或調整模型。
因此,(B) 是驗證集的主要用途。(A) 是訓練集的用途。(C) 是測試集的用途。(D) 與資料集劃分目的無關。
#6
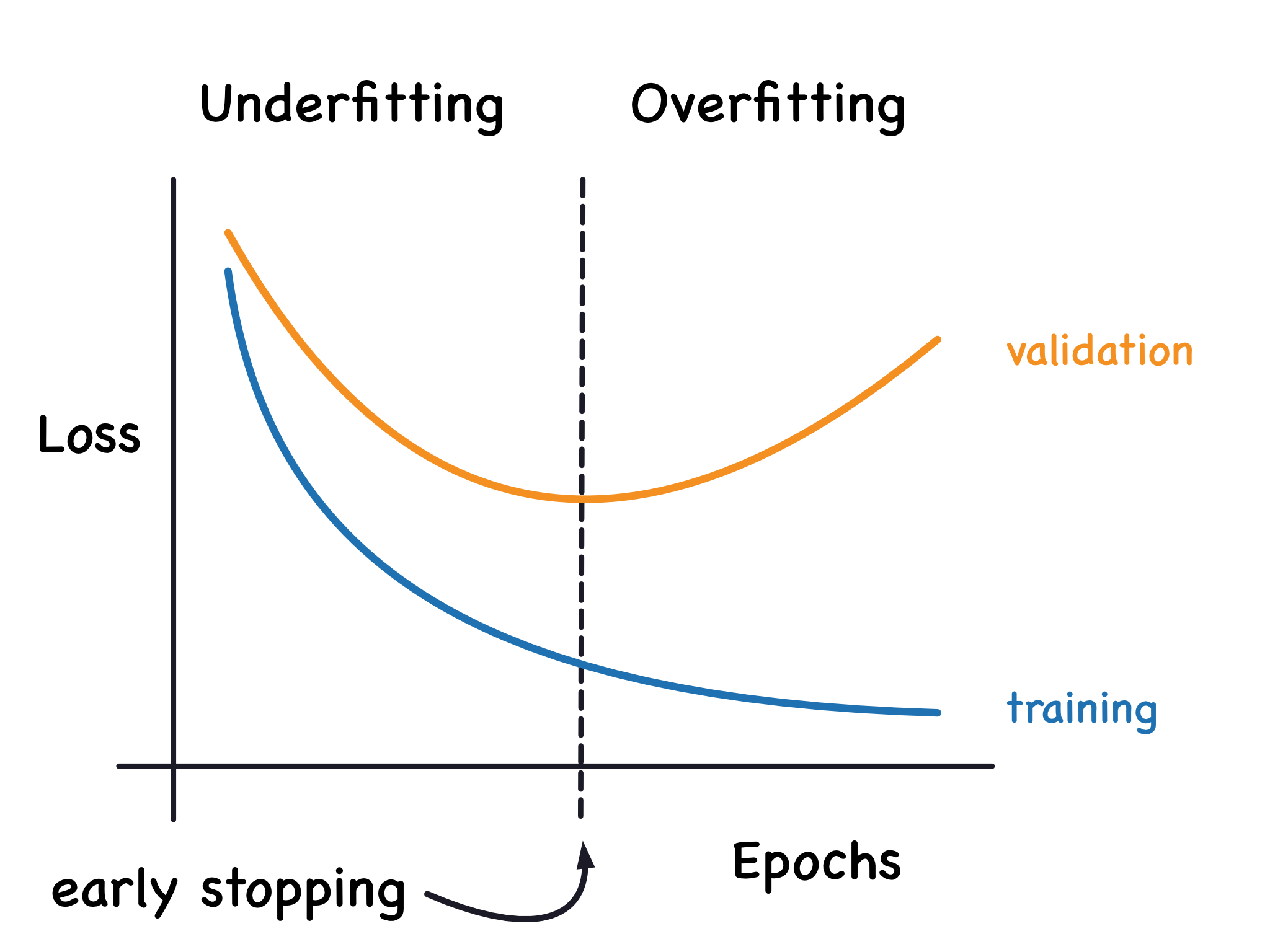
★★★★★
當一個機器學習模型在訓練集上表現極好,但在測試集或新資料上表現
很差時,這種現象被稱為什麼?
答案解析
過擬合 (Overfitting) 是機器學習中常見的問題,指的是模型
過度學習了訓練資料中的細節和噪聲,以至於模型對訓練集的數據擬合得非常好(
訓練誤差低),但卻失去了對新資料的泛化能力(測試誤差高)。
(A) 欠擬合是指模型過於簡單,未能捕捉到資料中的基本模式,導致在訓練集和測試集上表現都不好。
(C) 偏差通常與欠擬合相關,表示模型的預測值與真實值之間的系統性差異。
(D) 變異數通常與過擬合相關,表示模型對訓練資料微小變化的敏感度,高變異數意味著模型在不同訓練集上可能產生差異很大的結果。
(A) 欠擬合是指模型過於簡單,未能捕捉到資料中的基本模式,導致在訓練集和測試集上表現都不好。
(C) 偏差通常與欠擬合相關,表示模型的預測值與真實值之間的系統性差異。
(D) 變異數通常與過擬合相關,表示模型對訓練資料微小變化的敏感度,高變異數意味著模型在不同訓練集上可能產生差異很大的結果。
#7
★★★
傳統的程式設計與機器學習的主要區別在於?
答案解析
傳統程式設計是開發者明確地編寫規則和指令,告訴電腦如何處理輸入並產生輸出。而機器學習則是提供
大量的資料(包含輸入和期望的輸出,或只有輸入),讓
演算法自動從資料中學習模式和規則,然後用學到的模型來處理新的輸入。簡而言之,傳統程式是「
規則+資料 -> 答案」,機器學習是「資料+答案 -> 規則」。
(A) 機器學習非常依賴計算能力強的硬體。
(C) 機器學習可以處理各種資料類型,包括文字、圖像、聲音等。
(D) 傳統程式設計也能處理複雜問題,但對於模式識別、預測等任務,機器學習通常更有效。
(A) 機器學習非常依賴計算能力強的硬體。
(C) 機器學習可以處理各種資料類型,包括文字、圖像、聲音等。
(D) 傳統程式設計也能處理複雜問題,但對於模式識別、預測等任務,機器學習通常更有效。
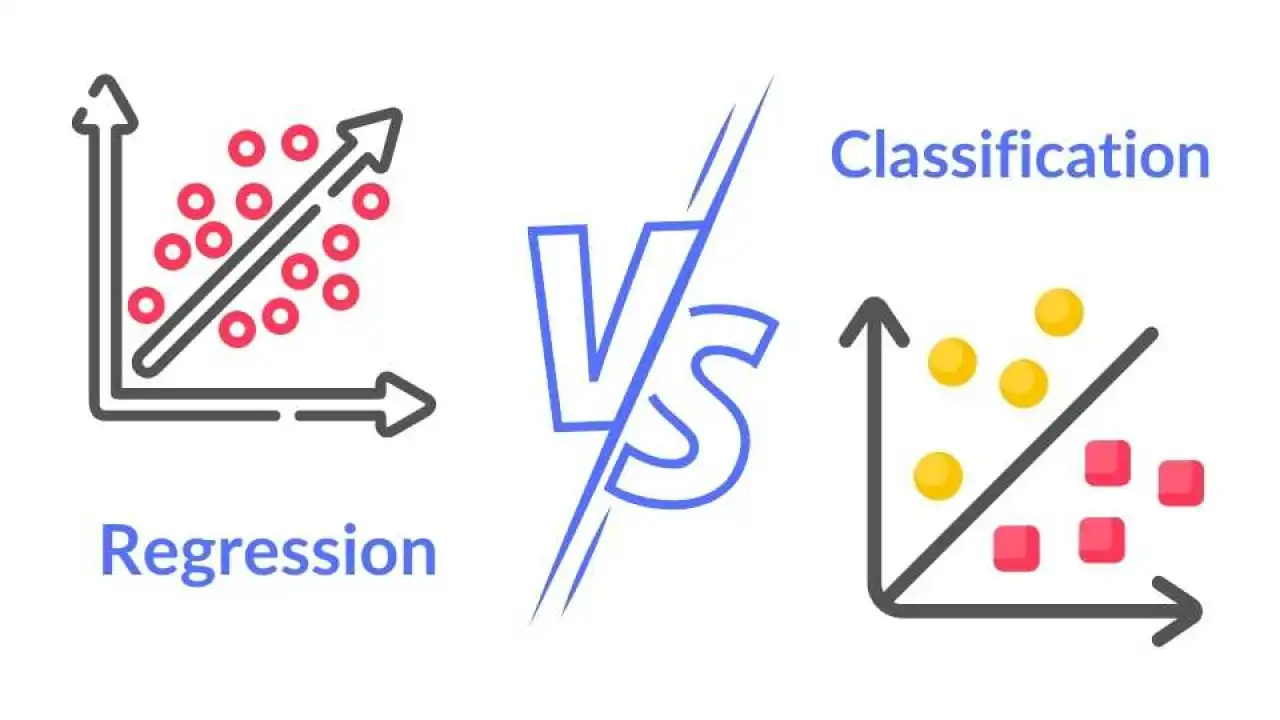
#8
★★★★
監督式學習可以解決哪兩種類型的機器學習問題?
答案解析
監督式學習是基於帶有標籤的訓練資料進行學習,主要解決兩大類問題:
1. 分類 (Classification): 預測輸入資料屬於 哪個預先定義的類別(離散值)。例如:判斷郵件是否為垃圾郵件(是/否)、辨識圖片中的動物(貓/狗/鳥)。
2. 迴歸 (Regression): 預測一個連續的數值。例如:預測房屋的價格、預測明天的氣溫。
(A) 分群和降維是非監督式學習的主要任務。(C) 包含 非監督式學習。(D) 強化學習是另一種學習範式。
1. 分類 (Classification): 預測輸入資料屬於 哪個預先定義的類別(離散值)。例如:判斷郵件是否為垃圾郵件(是/否)、辨識圖片中的動物(貓/狗/鳥)。
2. 迴歸 (Regression): 預測一個連續的數值。例如:預測房屋的價格、預測明天的氣溫。
(A) 分群和降維是非監督式學習的主要任務。(C) 包含 非監督式學習。(D) 強化學習是另一種學習範式。
#9
★★★★
下列哪種方法是常用來緩解機器學習模型過擬合 (Overfitting) 問題的技術?
答案解析
過擬合發生時,模型變得過於複雜,對訓練資料擬合過度。緩解過擬合的方法旨在降低模型的複雜度或
增加模型的泛化能力。
(A) 正則化是一種常用的技術,它透過在模型的損失函數 (Loss Function) 中加入一個 懲罰項(通常基於模型參數的大小),來限制模型的複雜度,從而防止模型過度擬合訓練資料。
(B) 增加模型複雜度通常會加劇過擬合。
(C) 使用更少的訓練資料會讓模型更難學習到資料的真實模式,可能導致欠擬合或更容易過擬合(如果資料量太少)。
(D) 驗證集是用來監控和調整模型以防止過擬合的,不使用驗證集會失去發現過擬合的機會。其他緩解方法還包括: 交叉驗證 (Cross-validation)、增加訓練資料、 特徵選擇 (Feature Selection)、早期停止 ( Early Stopping) 等。
(A) 正則化是一種常用的技術,它透過在模型的損失函數 (Loss Function) 中加入一個 懲罰項(通常基於模型參數的大小),來限制模型的複雜度,從而防止模型過度擬合訓練資料。
(B) 增加模型複雜度通常會加劇過擬合。
(C) 使用更少的訓練資料會讓模型更難學習到資料的真實模式,可能導致欠擬合或更容易過擬合(如果資料量太少)。
(D) 驗證集是用來監控和調整模型以防止過擬合的,不使用驗證集會失去發現過擬合的機會。其他緩解方法還包括: 交叉驗證 (Cross-validation)、增加訓練資料、 特徵選擇 (Feature Selection)、早期停止 ( Early Stopping) 等。
#10
★★★
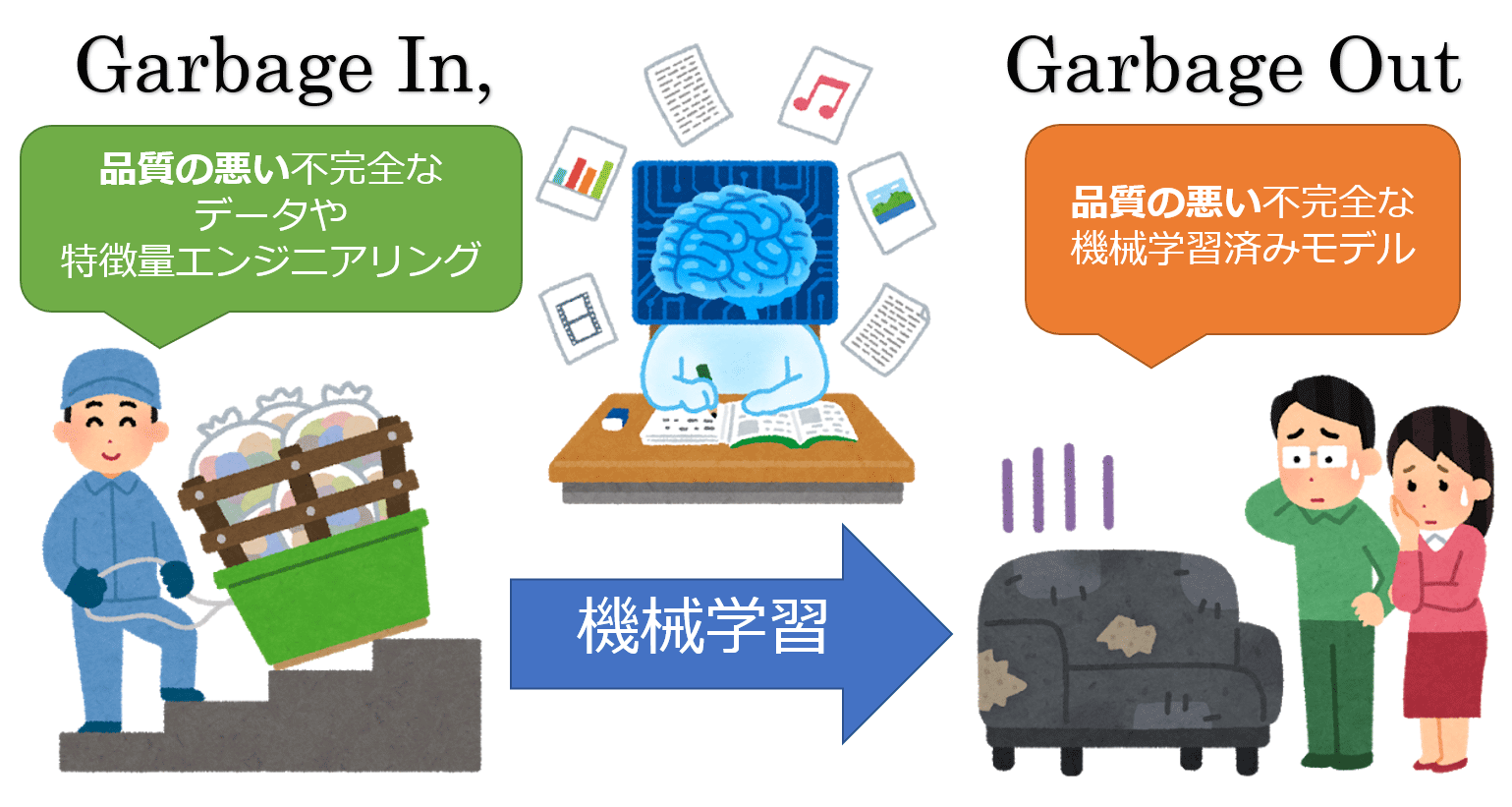
在機器學習中,"Garbage in, garbage out" (GIGO) 這句話強調了什麼的重要性?
答案解析
"Garbage in, garbage out" (GIGO) 是一句電腦科學的諺語,在機器學習領域尤其適用。它意味著如果
輸入到系統或模型的資料品質很差("垃圾"),那麼輸出的結果或預測也將是不可靠或無用的("垃圾")。這強調了
高品質、乾淨、相關的訓練資料對於建立有效和準確的機器學習模型至關重要。
(A) 複雜的模型不一定好,可能導致過擬合。(B) 最新的演算法不一定最適合特定問題。(D) 計算資源是必要的,但不能彌補資料品質差的問題。
(A) 複雜的模型不一定好,可能導致過擬合。(B) 最新的演算法不一定最適合特定問題。(D) 計算資源是必要的,但不能彌補資料品質差的問題。
#11
★★★★
哪種類型的機器學習涉及代理 (Agent) 在環境中採取行動並透過
獎勵或懲罰來學習最佳策略?
答案解析
強化學習的核心概念是讓一個代理(例如:機器人、遊戲AI)透過與
環境的互動來學習。代理會根據其行動獲得獎勵(正回饋)或
懲罰(負回饋),其目標是學習一套能夠最大化長期累積獎勵的策略(即一系列行動)。這與
監督式學習(需要標籤資料)和非監督式學習(尋找資料結構)的學習方式不同。
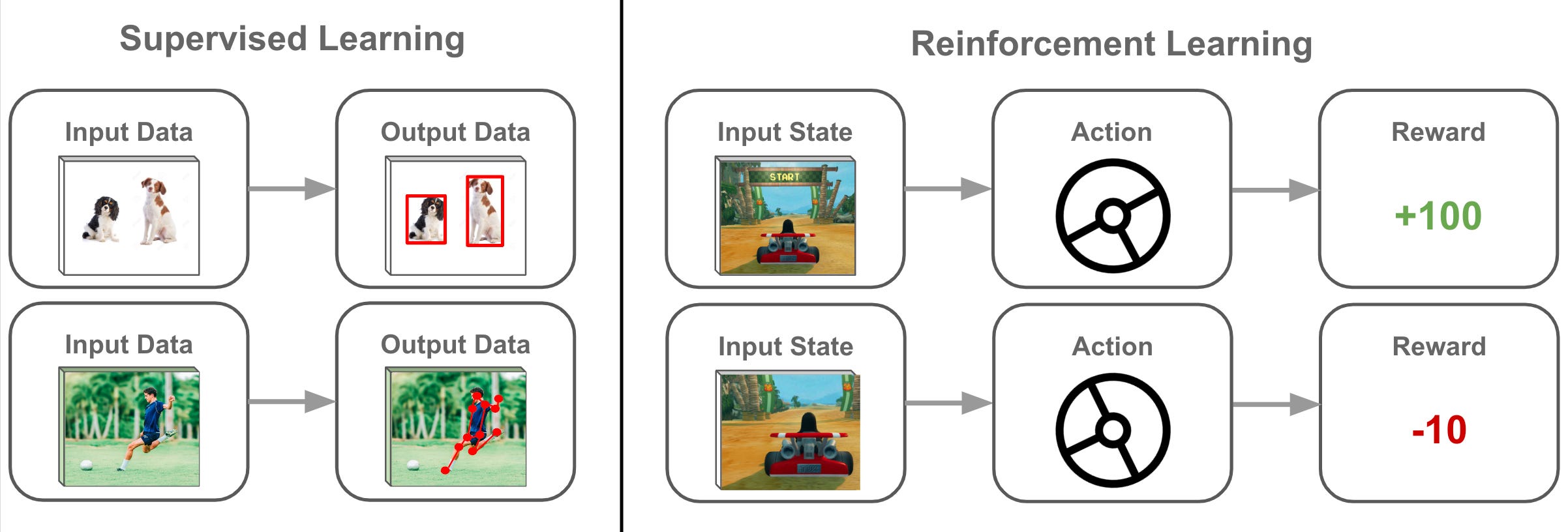
#12
★★★★
在評估分類 (Classification) 模型的性能時,準確率 (Accuracy) 指的是什麼?
答案解析
準確率 (Accuracy) 是評估分類模型最常用也是最直觀的指標之一。它的計算方式是:(正確預測的正例數 + 正確預測的負例數) /
總樣本數。換句話說,它衡量的是模型整體預測正確的比例。
然而,需要注意的是,在資料類別不平衡的情況下, 準確率可能不是一個好的評估指標。例如,如果99%的郵件都不是垃圾郵件,一個將所有郵件都預測為非垃圾郵件的模型也能達到99%的準確率,但它並沒有實際的辨識能力。在這種情況下, 精確率、召回率、F1分數等指標通常更具參考價值。
然而,需要注意的是,在資料類別不平衡的情況下, 準確率可能不是一個好的評估指標。例如,如果99%的郵件都不是垃圾郵件,一個將所有郵件都預測為非垃圾郵件的模型也能達到99%的準確率,但它並沒有實際的辨識能力。在這種情況下, 精確率、召回率、F1分數等指標通常更具參考價值。
#13
★★★★
為什麼在訓練機器學習模型之前,通常需要對資料進行預處理 (
Preprocessing)?
答案解析
真實世界的資料往往是不完整、不一致或充滿雜訊的。資料預處理是
機器學習流程中非常關鍵的一步,其目的包括:
* 資料清理:處理錯誤或不一致的資料。
* 處理缺失值:填補或刪除缺失的數據。
* 特徵縮放/標準化:將不同範圍的數值特徵調整到相似的尺度,避免某些特徵對模型影響過大。
* 特徵編碼:將類別型特徵轉換成數值格式,以便模型處理。
這些步驟有助於提高資料品質,使得模型能夠更有效地學習,並獲得更準確、更穩定的結果。
(A) 增加雜訊通常會降低模型性能。(B) 不一定所有資料都要轉成文字。(D) 預處理有時會增加資料維度(如獨熱編碼),不一定是減少大小。
* 資料清理:處理錯誤或不一致的資料。
* 處理缺失值:填補或刪除缺失的數據。
* 特徵縮放/標準化:將不同範圍的數值特徵調整到相似的尺度,避免某些特徵對模型影響過大。
* 特徵編碼:將類別型特徵轉換成數值格式,以便模型處理。
這些步驟有助於提高資料品質,使得模型能夠更有效地學習,並獲得更準確、更穩定的結果。
(A) 增加雜訊通常會降低模型性能。(B) 不一定所有資料都要轉成文字。(D) 預處理有時會增加資料維度(如獨熱編碼),不一定是減少大小。
#14
★★★★
當機器學習模型在訓練集和測試集上的表現都
很差,無法捕捉到資料中的基本趨勢時,稱為什麼?
答案解析
欠擬合 (Underfitting) 指的是機器學習模型
過於簡單,無法很好地捕捉到資料中的複雜模式或趨勢。這導致模型不僅在訓練集上表現不佳(
訓練誤差高),在測試集或新資料上的表現同樣很差(
測試誤差也高)。這通常意味著模型的偏差較高。
(B) 過擬合是在訓練集表現好,測試集表現差。(C) 高變異數通常與過擬合相關。(D) 低 偏差通常表示模型能較好地擬合訓練資料,可能伴隨著高變異數(過擬合)。
(B) 過擬合是在訓練集表現好,測試集表現差。(C) 高變異數通常與過擬合相關。(D) 低 偏差通常表示模型能較好地擬合訓練資料,可能伴隨著高變異數(過擬合)。
#15
★★★★★
在一個二元分類問題中(例如判斷是否為垃圾郵件),如果模型將一個實際是正例的樣本
錯誤地預測為負例,這種錯誤被稱為什麼?
答案解析
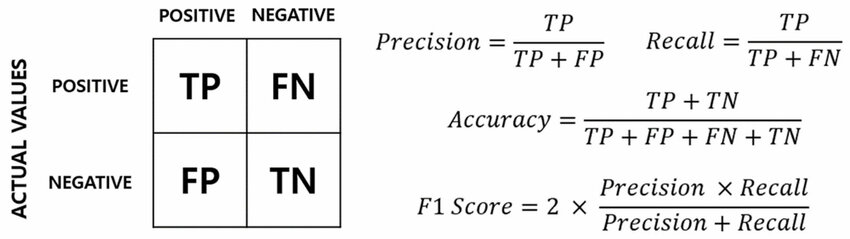
在二元分類的混淆矩陣 (Confusion Matrix) 中,四種預測結果定義如下:
* 真陽性 (True Positive, TP): 實際是正例,模型也預測為 正例。
* 真陰性 (True Negative, TN): 實際是負例,模型也預測為 負例。
* 偽陽性 (False Positive, FP): 實際是負例,但模型 錯誤地預測為正例(第一型錯誤 Type I Error)。
* 偽陰性 (False Negative, FN): 實際是正例,但模型 錯誤地預測為負例(第二型錯誤 Type II Error)。
題目描述的是「實際是正例,錯誤預測為負例」,因此是偽陰性 (FN)。
* 真陽性 (True Positive, TP): 實際是正例,模型也預測為 正例。
* 真陰性 (True Negative, TN): 實際是負例,模型也預測為 負例。
* 偽陽性 (False Positive, FP): 實際是負例,但模型 錯誤地預測為正例(第一型錯誤 Type I Error)。
* 偽陰性 (False Negative, FN): 實際是正例,但模型 錯誤地預測為負例(第二型錯誤 Type II Error)。
題目描述的是「實際是正例,錯誤預測為負例」,因此是偽陰性 (FN)。
#16
★★★
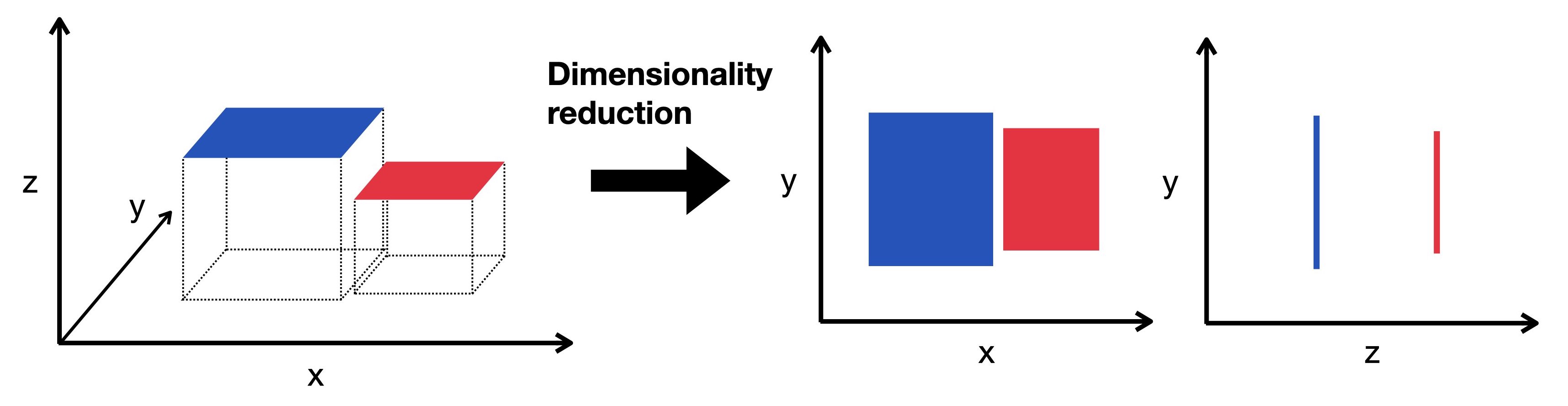
非監督式學習中的降維 (Dimensionality Reduction) 技術,其主要目的是什麼?
答案解析
降維是非監督式學習中的一類技術,旨在減少資料集中的特徵數量(即維度),同時
盡可能地保留原始資料中的重要資訊和結構。降維的主要目的包括:
* 降低計算複雜度和存儲需求。
* 去除冗餘和不相關的特徵。
* 有助於資料視覺化(例如降到二維或三維)。
* 可能緩解維度災難 (Curse of Dimensionality) 問題,有時能提高模型性能。
常用的降維技術有主成分分析 (PCA, Principal Component Analysis)。
(A) 分群是另一種非監督式學習任務。(B) 預測連續值是迴歸任務。(D) 添加標籤是監督式學習的範疇。
* 降低計算複雜度和存儲需求。
* 去除冗餘和不相關的特徵。
* 有助於資料視覺化(例如降到二維或三維)。
* 可能緩解維度災難 (Curse of Dimensionality) 問題,有時能提高模型性能。
常用的降維技術有主成分分析 (PCA, Principal Component Analysis)。
(A) 分群是另一種非監督式學習任務。(B) 預測連續值是迴歸任務。(D) 添加標籤是監督式學習的範疇。
#17
★★★
在機器學習中,什麼是交叉驗證 (Cross-validation)?
答案解析
交叉驗證是一種用來評估機器學習模型泛化能力的統計方法,特別是在
資料量有限時很有用。它將原始資料集劃分成多個子集(稱為"摺",fold),然後進行
多次訓練和驗證。在每次迭代中,選取其中一個子集作為驗證集,其餘子集作為
訓練集。重複這個過程,直到每個子集都作為驗證集一次。最後將多次驗證的結果
平均,得到一個更穩定、更可靠的模型性能評估。
常用的交叉驗證方法是 K-摺交叉驗證 (K-Fold Cross-validation),將資料分成 K 個子集。
交叉驗證有助於避免單次劃分訓練/驗證集可能帶來的偏差,更全面地評估模型性能,並輔助進行模型選擇和超參數調整。
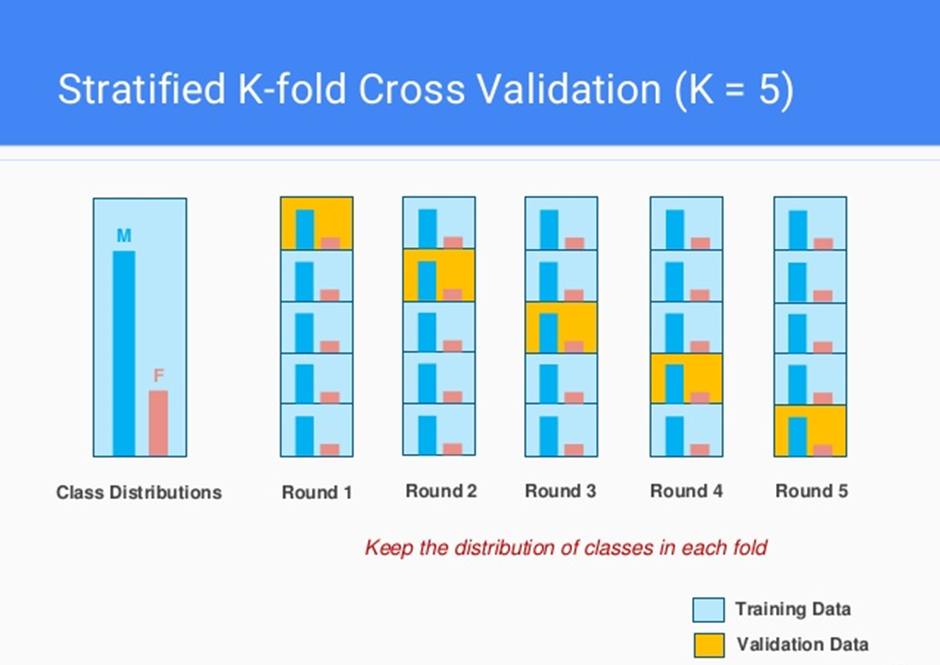
常用的交叉驗證方法是 K-摺交叉驗證 (K-Fold Cross-validation),將資料分成 K 個子集。
交叉驗證有助於避免單次劃分訓練/驗證集可能帶來的偏差,更全面地評估模型性能,並輔助進行模型選擇和超參數調整。
#18
★★
強化學習中的「探索 (Exploration) vs 利用 (
Exploitation)」權衡指的是什麼?
答案解析
在強化學習中,代理 (Agent) 需要在環境中做出一系列決策以最大化獎勵。這時會面臨一個基本的權衡:
* 利用 (Exploitation): 指代理 根據當前已知的資訊,選擇能帶來最高預期獎勵的行動。這是利用已有的經驗。
* 探索 (Exploration): 指代理嘗試一些之前未曾嘗試過或較少嘗試的行動,目的是 發現環境中可能存在的、能帶來更高獎勵的新策略,即使這些行動當前的預期獎勵不高。
過度利用可能導致代理陷入局部最優解,錯過更好的策略;過度探索則可能浪費時間在低效的行動上。因此,如何在探索和利用之間取得平衡是強化學習中的一個核心挑戰。
* 利用 (Exploitation): 指代理 根據當前已知的資訊,選擇能帶來最高預期獎勵的行動。這是利用已有的經驗。
* 探索 (Exploration): 指代理嘗試一些之前未曾嘗試過或較少嘗試的行動,目的是 發現環境中可能存在的、能帶來更高獎勵的新策略,即使這些行動當前的預期獎勵不高。
過度利用可能導致代理陷入局部最優解,錯過更好的策略;過度探索則可能浪費時間在低效的行動上。因此,如何在探索和利用之間取得平衡是強化學習中的一個核心挑戰。
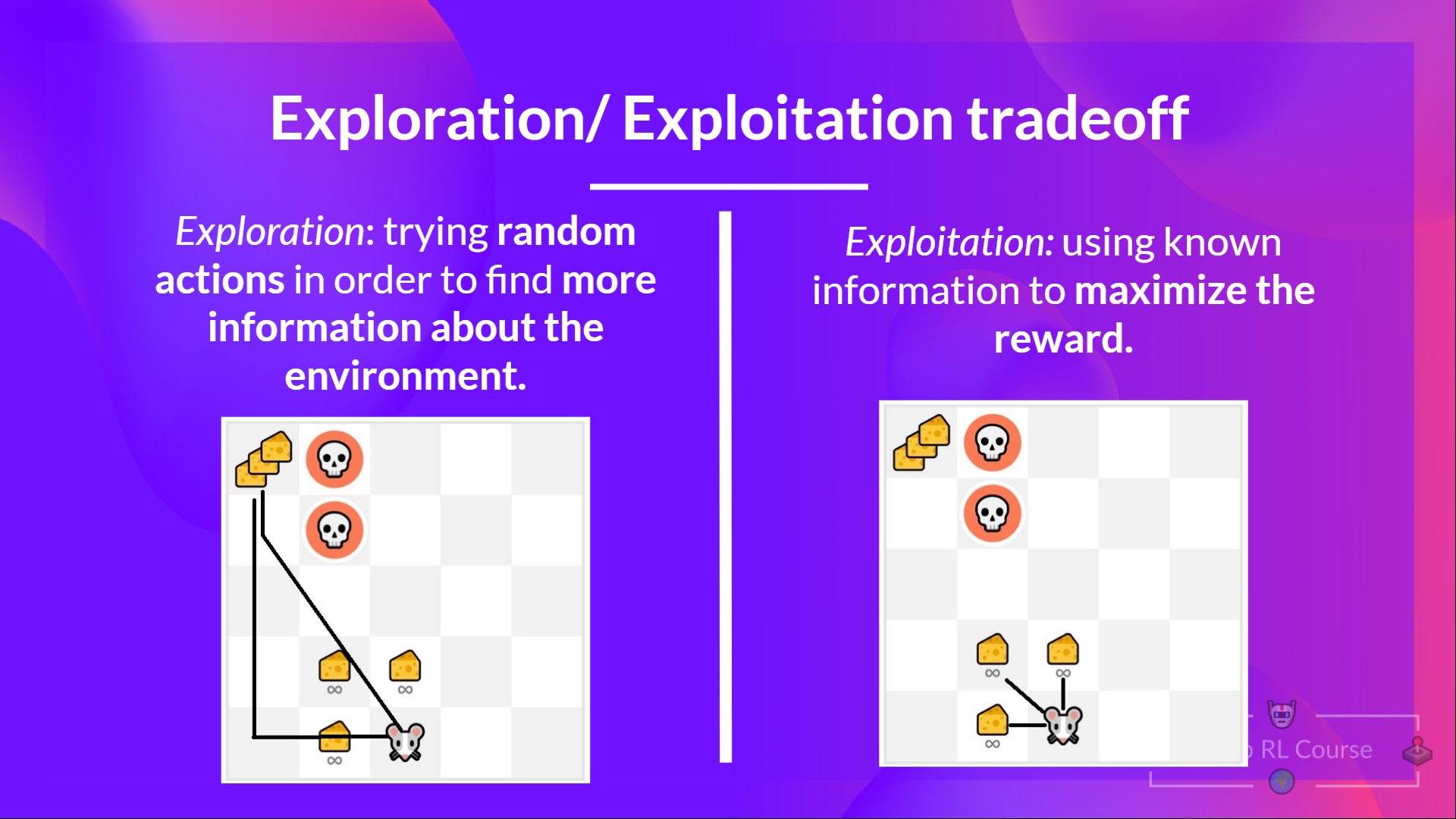
#19
★★
下列何者不是機器學習的典型應用?
答案解析
機器學習擅長處理需要從資料中學習模式的任務。
(A) 圖像識別是讓電腦理解圖像內容,是機器學習(特別是深度學習)的重要應用。
(B) 自然語言處理是讓電腦理解和生成人類語言,也是機器學習的關鍵領域。
(C) 推薦系統根據使用者歷史行為預測其偏好,推薦相關商品或內容,廣泛應用機器學習技術。
(D) 編寫操作系統的核心程式碼需要精確、可靠的邏輯和對硬體的底層控制,這通常依賴於 傳統的、基於規則的程式設計,而非從資料中學習的機器學習方法。雖然機器學習可能用於操作系統的某些輔助功能(如性能優化),但核心開發本身不是典型的機器學習應用。
(A) 圖像識別是讓電腦理解圖像內容,是機器學習(特別是深度學習)的重要應用。
(B) 自然語言處理是讓電腦理解和生成人類語言,也是機器學習的關鍵領域。
(C) 推薦系統根據使用者歷史行為預測其偏好,推薦相關商品或內容,廣泛應用機器學習技術。
(D) 編寫操作系統的核心程式碼需要精確、可靠的邏輯和對硬體的底層控制,這通常依賴於 傳統的、基於規則的程式設計,而非從資料中學習的機器學習方法。雖然機器學習可能用於操作系統的某些輔助功能(如性能優化),但核心開發本身不是典型的機器學習應用。
#20
★★★
在評估迴歸 (Regression) 模型的性能時,常用的指標 均方誤差 (MSE,
Mean Squared Error) 是如何計算的?
答案解析
均方誤差 (MSE) 是衡量迴歸模型預測精度的常用指標。它的計算方法是:先計算
每個樣本的預測值與實際值之間的差,然後將這些差值平方,最後計算所有
平方差的平均值。
公式:MSE = (1/n) * Σ(yᵢ - ŷᵢ)²,其中 n 是樣本數量,yᵢ 是第 i 個樣本的實際值,ŷᵢ 是第 i 個樣本的預測值。
均方誤差的值越小,表示模型的預測結果越接近實際值,性能越好。對差值進行平方可以放大較大的誤差,並確保誤差值為正。
(A) 描述的是平均絕對誤差 (MAE, Mean Absolute Error)。(C) 差的平均值可能會因為正負誤差抵消而失去意義。(D) 差的平方和沒有除以樣本數n。
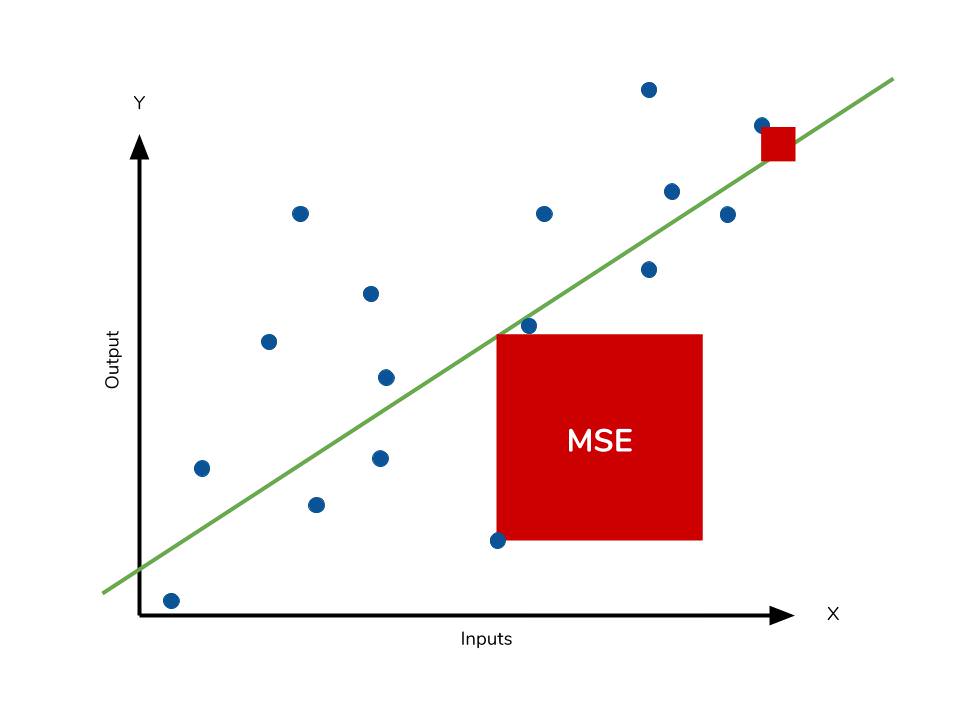
公式:MSE = (1/n) * Σ(yᵢ - ŷᵢ)²,其中 n 是樣本數量,yᵢ 是第 i 個樣本的實際值,ŷᵢ 是第 i 個樣本的預測值。
均方誤差的值越小,表示模型的預測結果越接近實際值,性能越好。對差值進行平方可以放大較大的誤差,並確保誤差值為正。
(A) 描述的是平均絕對誤差 (MAE, Mean Absolute Error)。(C) 差的平均值可能會因為正負誤差抵消而失去意義。(D) 差的平方和沒有除以樣本數n。
#21
★★★
在監督式學習的分類問題中,如果輸出的類別只有兩種(例如:是/否,成功/失敗),這種類型的分類稱為什麼?
答案解析
分類問題根據輸出類別的數量可以區分:
* 二元分類: 輸出的目標類別只有兩種,互斥。例如:判斷郵件是否為垃圾郵件、判斷客戶是否會流失。
* 多元分類: 輸出的目標類別有 多個(三個或以上),且每個樣本只能屬於其中一個類別。例如:手寫數字辨識(0-9)、辨識圖片中的動物(貓/狗/鳥)。
* 多標籤分類: 每個樣本可以同時屬於多個類別。例如:一部電影可以同時被標記為「動作片」和「科幻片」。
(D) 迴歸問題是預測連續值,不是分類問題。
* 二元分類: 輸出的目標類別只有兩種,互斥。例如:判斷郵件是否為垃圾郵件、判斷客戶是否會流失。
* 多元分類: 輸出的目標類別有 多個(三個或以上),且每個樣本只能屬於其中一個類別。例如:手寫數字辨識(0-9)、辨識圖片中的動物(貓/狗/鳥)。
* 多標籤分類: 每個樣本可以同時屬於多個類別。例如:一部電影可以同時被標記為「動作片」和「科幻片」。
(D) 迴歸問題是預測連續值,不是分類問題。
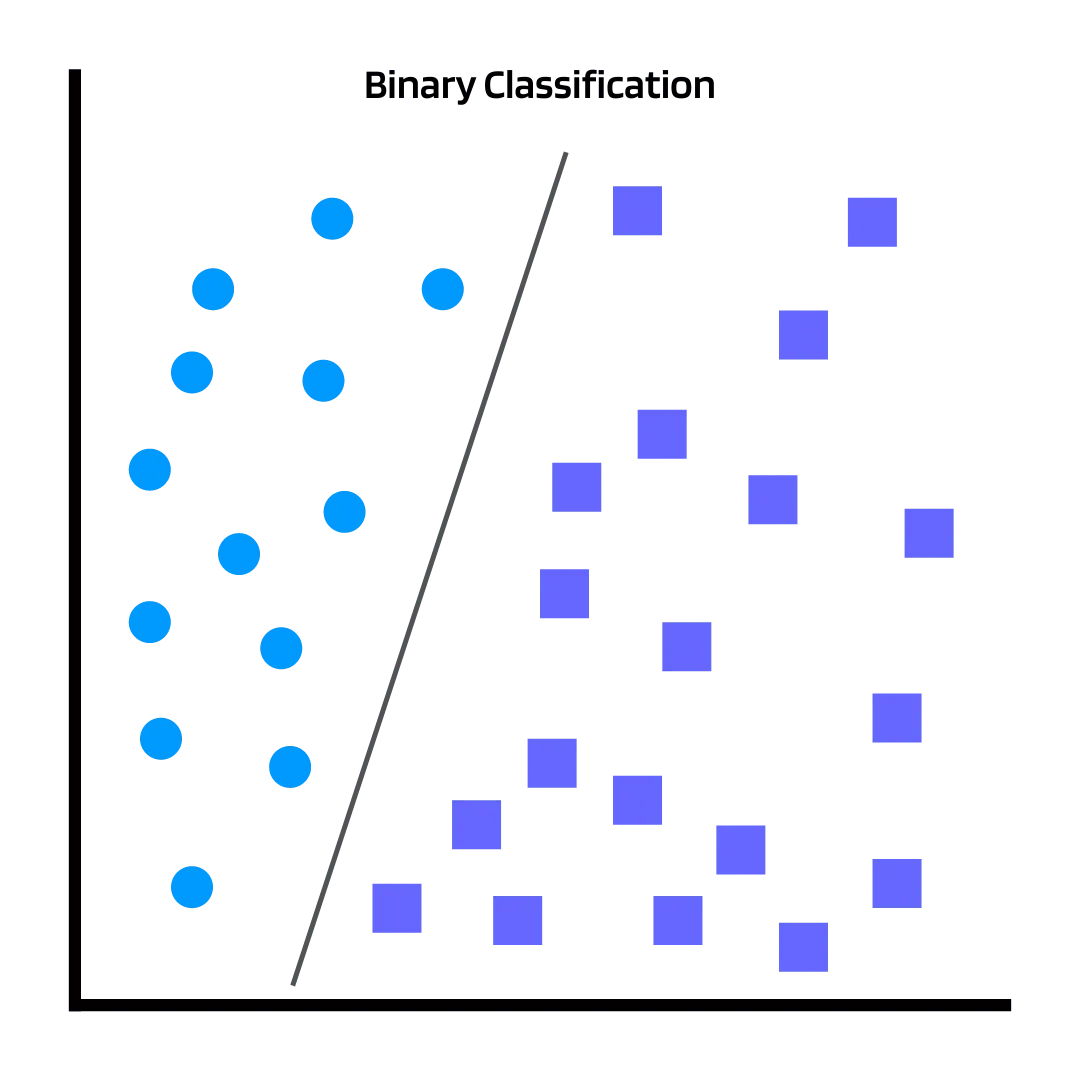
#22
★★★
K-均值 (K-Means) 演算法是一種常見的機器學習演算法,它主要用於解決哪種類型的問題?
答案解析
K-均值 (K-Means) 是一種非常流行的分群演算法,屬於
非監督式學習。它的目標是將未標記的資料點自動劃分成 K
個不同的群組(簇),使得同一個群組內的資料點彼此相似度較高,而不同群組間的資料點相似度較低。它通過迭代計算每個群組的中心點(質心)並將資料點分配給最近的中心點來實現分群。
(A) 分類需要有標籤的資料。(B) 迴歸預測連續值。(D) 強化學習涉及代理與環境互動學習。
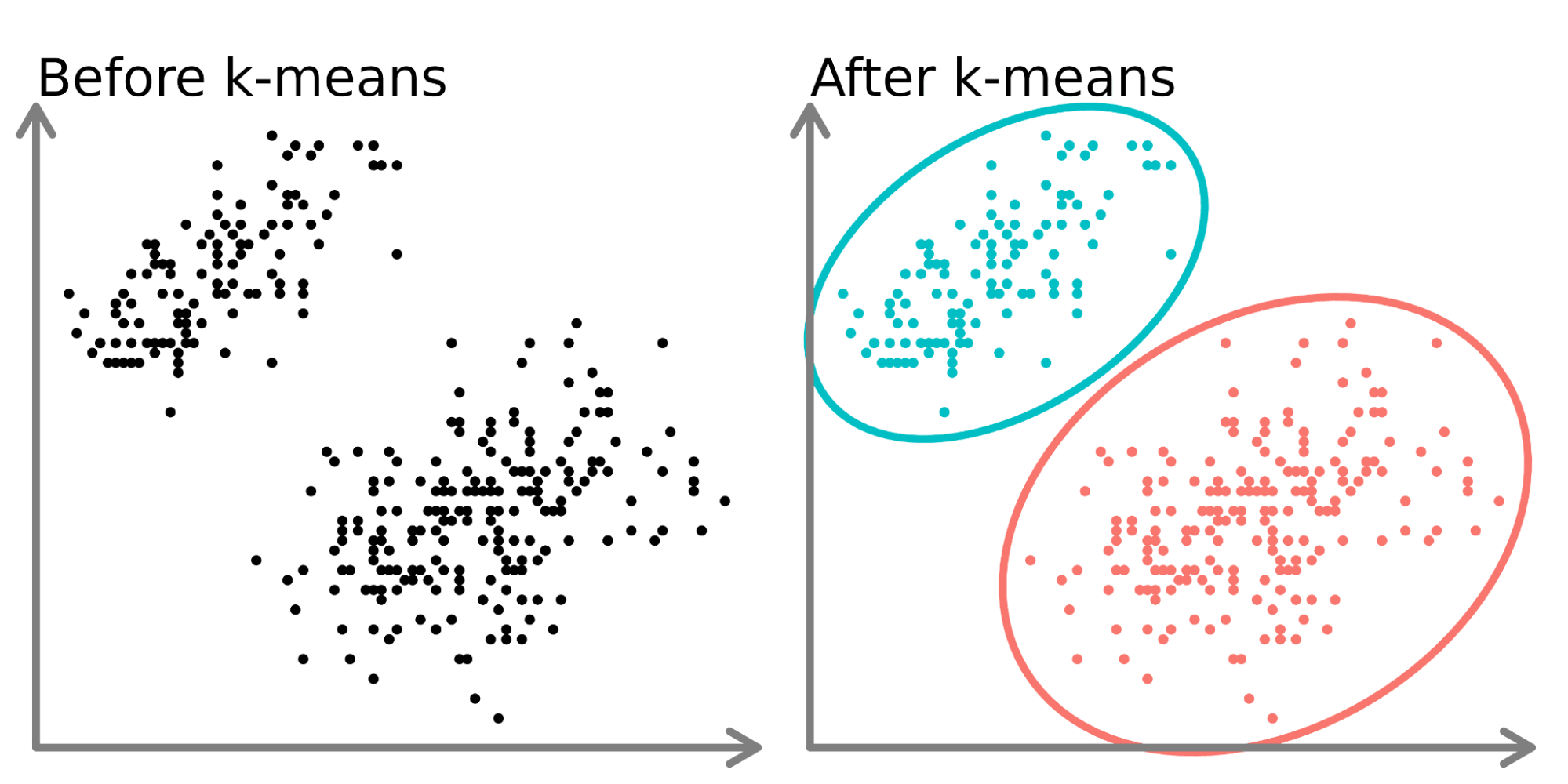
(A) 分類需要有標籤的資料。(B) 迴歸預測連續值。(D) 強化學習涉及代理與環境互動學習。
#23
★★★★
在機器學習中,將類別型資料(例如:顏色 "紅"、"綠"、"藍")轉換成模型可以處理的
數值形式的過程稱為什麼?
答案解析
大多數機器學習演算法需要數值型的輸入資料。然而,真實世界的資料常常包含
類別型的特徵(非數值的,如顏色、性別、國家等)。特徵編碼就是將這些
類別型特徵轉換成數值表示的過程,以便機器學習模型能夠理解和處理。常見的編碼方法包括獨熱編碼 (
One-Hot Encoding) 和標籤編碼 (Label Encoding)。
(A) 特徵縮放是調整數值特徵的範圍。(B) 特徵選擇是從現有特徵中選出最重要的子集。(D) 特徵提取是從原始資料中創建新的、更有意義的特徵(通常是降維的一部分)。
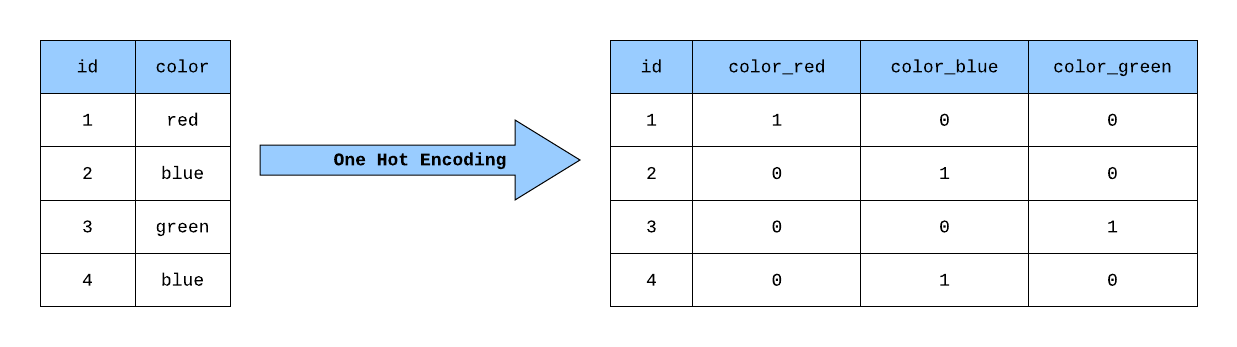
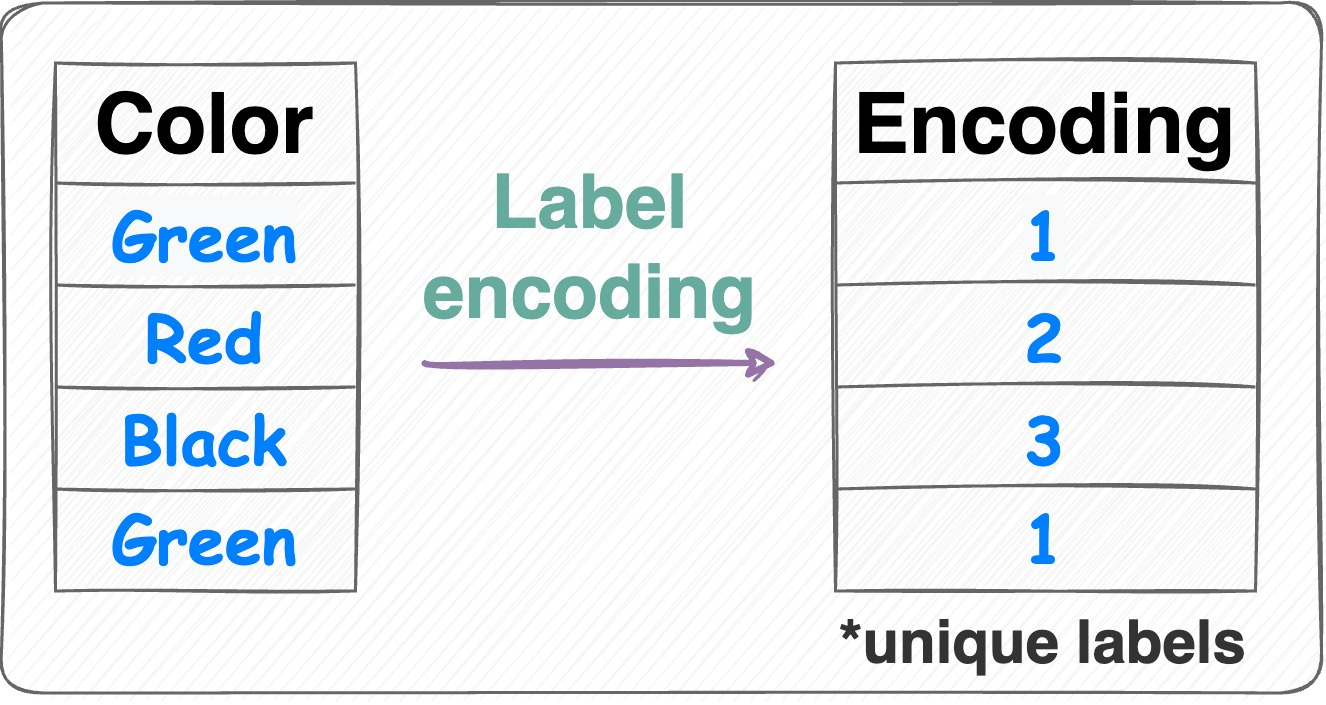
(A) 特徵縮放是調整數值特徵的範圍。(B) 特徵選擇是從現有特徵中選出最重要的子集。(D) 特徵提取是從原始資料中創建新的、更有意義的特徵(通常是降維的一部分)。
#24
★★★
為什麼需要將資料集劃分成訓練集和測試集?
答案解析
將資料集劃分成訓練集和測試集是機器學習中評估模型性能的標準做法。其主要目的是:
模型使用訓練集進行學習。如果我們用相同的訓練集來評估模型,那麼表現好的模型可能只是死記硬背了訓練資料(即 過擬合),而無法對新的、未見過的資料做出準確預測。
測試集包含模型在訓練過程中從未見過的資料。通過在測試集上評估模型的表現,我們可以了解模型對新資料的 泛化能力如何,即模型是否真正學到了通用的模式,而不是僅僅記住了訓練樣本。這是衡量模型在真實世界應用中表現好壞的關鍵。
(A) 劃分資料集本身不一定加快訓練速度。(B) 目標是泛化,不是死記硬背。(D) 劃分資料集並不能減少總資料量的需求。
模型使用訓練集進行學習。如果我們用相同的訓練集來評估模型,那麼表現好的模型可能只是死記硬背了訓練資料(即 過擬合),而無法對新的、未見過的資料做出準確預測。
測試集包含模型在訓練過程中從未見過的資料。通過在測試集上評估模型的表現,我們可以了解模型對新資料的 泛化能力如何,即模型是否真正學到了通用的模式,而不是僅僅記住了訓練樣本。這是衡量模型在真實世界應用中表現好壞的關鍵。
(A) 劃分資料集本身不一定加快訓練速度。(B) 目標是泛化,不是死記硬背。(D) 劃分資料集並不能減少總資料量的需求。
#25
★★★
解決欠擬合 (Underfitting) 問題的常見方法不包括下列哪一項?
答案解析
欠擬合表示模型過於簡單,未能捕捉資料模式。因此,解決欠擬合的方法通常是讓模型更有能力學習複雜模式。
(A) 增加模型複雜度可以讓模型有能力學習更複雜的關係。
(B) 增加相關特徵可以提供模型更多有用的資訊來學習。
(C) 如果模型是因為訓練不足而表現不佳,延長訓練時間可能會有幫助。
(D) 正則化是用來限制模型複雜度以防止過擬合的。增加正則化強度會使模型更簡單,可能會 加劇欠擬合問題,而不是解決它。
(A) 增加模型複雜度可以讓模型有能力學習更複雜的關係。
(B) 增加相關特徵可以提供模型更多有用的資訊來學習。
(C) 如果模型是因為訓練不足而表現不佳,延長訓練時間可能會有幫助。
(D) 正則化是用來限制模型複雜度以防止過擬合的。增加正則化強度會使模型更簡單,可能會 加劇欠擬合問題,而不是解決它。
#26
★★★★
在分類任務中,如果我們更關心找出所有實際為正例的樣本(例如:在疾病篩檢中找出所有患者),應該關注哪個評估指標?
答案解析
* 召回率 (Recall),也稱為敏感度 (Sensitivity) 或
真陽性率 (True Positive Rate, TPR),衡量的是
所有實際為正例的樣本中,有多少被模型成功預測為正例。計算公式為:TP / (TP + FN)。
當我們不希望漏掉任何一個實際的正例時(即最小化偽陰性 FN), 召回率就是一個非常重要的指標。例如,在疾病篩檢中,漏診(偽陰性)的代價很高,所以我們希望召回率盡可能高。
* 精確率 (Precision) 衡量的是模型預測為正例的樣本中,有多少是真正例。當我們不希望誤判(最小化 偽陽性 FP)時,精確率更重要。
* 準確率是整體正確率。
* 特異度 (Specificity) 衡量的是實際為負例的樣本中,有多少被成功預測為負例(TN / (TN + FP)),關心的是正確找出負例的能力。
當我們不希望漏掉任何一個實際的正例時(即最小化偽陰性 FN), 召回率就是一個非常重要的指標。例如,在疾病篩檢中,漏診(偽陰性)的代價很高,所以我們希望召回率盡可能高。
* 精確率 (Precision) 衡量的是模型預測為正例的樣本中,有多少是真正例。當我們不希望誤判(最小化 偽陽性 FP)時,精確率更重要。
* 準確率是整體正確率。
* 特異度 (Specificity) 衡量的是實際為負例的樣本中,有多少被成功預測為負例(TN / (TN + FP)),關心的是正確找出負例的能力。
#27
★★★
什麼是特徵工程 (Feature Engineering)?
答案解析
特徵工程是機器學習流程中極其重要的一環。它指的是運用對資料和問題領域的深入理解,對
原始資料進行轉換、組合或創建新的特徵,目的是讓這些新的特徵能
更好地被模型所利用,從而提高模型的預測準確性或泛化能力。好的特徵工程往往比選擇複雜的模型更能帶來顯著的性能提升。
它可能包括資料清理、格式轉換、數值化、離散化、特徵交叉、特徵選擇等多種操作。
它可能包括資料清理、格式轉換、數值化、離散化、特徵交叉、特徵選擇等多種操作。
#28
★★★
線性迴歸 (Linear Regression) 模型主要用於解決哪類問題?
答案解析
線性迴歸是一種基本的監督式學習演算法,其目標是找到一個線性函數,能夠最好地
擬合輸入特徵和輸出變數之間的關係,並用這個函數來預測一個連續的數值型輸出。因此,它主要用於解決
迴歸問題,例如預測房價、預測氣溫、預測銷售額等。
(A) 分類問題預測離散類別。(C) 分群是非監督式學習,用於找出資料結構。(D) 降維是非監督式學習,用於減少特徵數量。
(A) 分類問題預測離散類別。(C) 分群是非監督式學習,用於找出資料結構。(D) 降維是非監督式學習,用於減少特徵數量。
#29
★★★
在強化學習中,「獎勵 (Reward)」訊號扮演什麼角色?
答案解析
獎勵是強化學習中的核心概念之一。它是環境給予代理的一個回饋訊號,用來
評估代理剛剛採取的行動的好壞。正獎勵表示行動是好的,負獎勵(懲罰)表示行動是壞的。代理的目標是學習一個策略,使其在與環境的互動過程中能夠獲得最大化的累積獎勵。
(A) 描述環境狀態的是狀態 (State)。(B) 是行動空間 ( Action Space)。(D) 策略是代理根據狀態選擇行動的規則。
(A) 描述環境狀態的是狀態 (State)。(B) 是行動空間 ( Action Space)。(D) 策略是代理根據狀態選擇行動的規則。
#30
★★★
在處理文字資料進行機器學習時,將文字轉換成數值向量的過程稱為什麼?
答案解析
機器學習模型通常無法直接處理原始的文字資料,需要將文字轉換成數值形式的向量。這個過程稱為
文字表示。常見的技術包括:
* 詞袋模型 (Bag-of-Words, BoW)
* TF-IDF (Term Frequency-Inverse Document Frequency)
* 詞嵌入 (Word Embedding),例如 Word2Vec, GloVe, FastText 等,它們能將詞語映射到低維度的密集向量,捕捉詞語間的語義關係。
(B), (C), (D) 都是利用機器學習處理文字的具體任務,而不是將文字轉換成數值的過程。
* 詞袋模型 (Bag-of-Words, BoW)
* TF-IDF (Term Frequency-Inverse Document Frequency)
* 詞嵌入 (Word Embedding),例如 Word2Vec, GloVe, FastText 等,它們能將詞語映射到低維度的密集向量,捕捉詞語間的語義關係。
(B), (C), (D) 都是利用機器學習處理文字的具體任務,而不是將文字轉換成數值的過程。
#31
★★★★
在一個典型的機器學習專案中,哪個階段通常花費的時間最多?
答案解析
儘管模型訓練和調優很重要,但在實際的機器學習專案中,資料相關的工作,包括
收集來自不同來源的資料、理解資料、清理髒數據、處理
缺失值、進行特徵工程以及將資料轉換成適合模型使用的格式等
預處理步驟,通常會佔據整個專案絕大部分的時間和精力(常常超過 60%-80%)。因為資料的品質直接決定了模型性能的上限。
#32
★★★
「偏差-變異數權衡」(Bias-Variance Tradeoff) 是機器學習中的一個重要概念,它描述了什麼樣的關係?
答案解析
偏差-變異數權衡描述了模型預測誤差的兩個主要來源之間的關係:
* 偏差 (Bias): 指模型的預測值與實際值之間的系統性差異,高偏差通常表示模型欠擬合。
* 變異數 (Variance): 指模型預測結果對於訓練資料微小變化的敏感度,高變異數通常表示模型過擬合。
通常情況下,降低偏差(例如使用更複雜的模型)會增加變異數,而降低變異數(例如使用更簡單的模型或正則化)會增加偏差。理想的模型是在偏差和變異數之間找到一個 平衡點,以最小化總體預測誤差。
* 偏差 (Bias): 指模型的預測值與實際值之間的系統性差異,高偏差通常表示模型欠擬合。
* 變異數 (Variance): 指模型預測結果對於訓練資料微小變化的敏感度,高變異數通常表示模型過擬合。
通常情況下,降低偏差(例如使用更複雜的模型)會增加變異數,而降低變異數(例如使用更簡單的模型或正則化)會增加偏差。理想的模型是在偏差和變異數之間找到一個 平衡點,以最小化總體預測誤差。
#33
★★
在機器學習模型評估中,混淆矩陣 (Confusion Matrix) 主要用於評估哪種類型模型的性能?
答案解析
混淆矩陣是一種常用的視覺化工具,專門用於
評估分類模型的性能。它以矩陣的形式展示了模型預測的類別與實際類別之間的對應關係,清晰地顯示了真陽性 (
TP)、真陰性 (TN)、偽陽性 (FP) 和
偽陰性 (FN) 的數量。基於混淆矩陣,可以計算出準確率、精確率、
召回率、F1分數等多種評估指標。
迴歸模型通常使用 MSE, MAE, R² 等指標評估。分群模型有輪廓係數等指標。強化學習評估累積獎勵。
迴歸模型通常使用 MSE, MAE, R² 等指標評估。分群模型有輪廓係數等指標。強化學習評估累積獎勵。
#34
★★
下列哪個演算法不是典型的監督式學習演算法?
答案解析
(A) 支持向量機 (SVM, Support Vector Machine) 主要用於分類,也可進行
迴歸,是監督式學習。
(B) 決策樹可以用於分類和迴歸,是監督式學習。
(C) 邏輯迴歸雖然名為迴歸,但主要用於二元分類問題,是監督式學習。
(D) 主成分分析 (PCA) 是一種常用的降維技術,它在 沒有標籤的情況下尋找資料的主要變異方向,屬於非監督式學習。
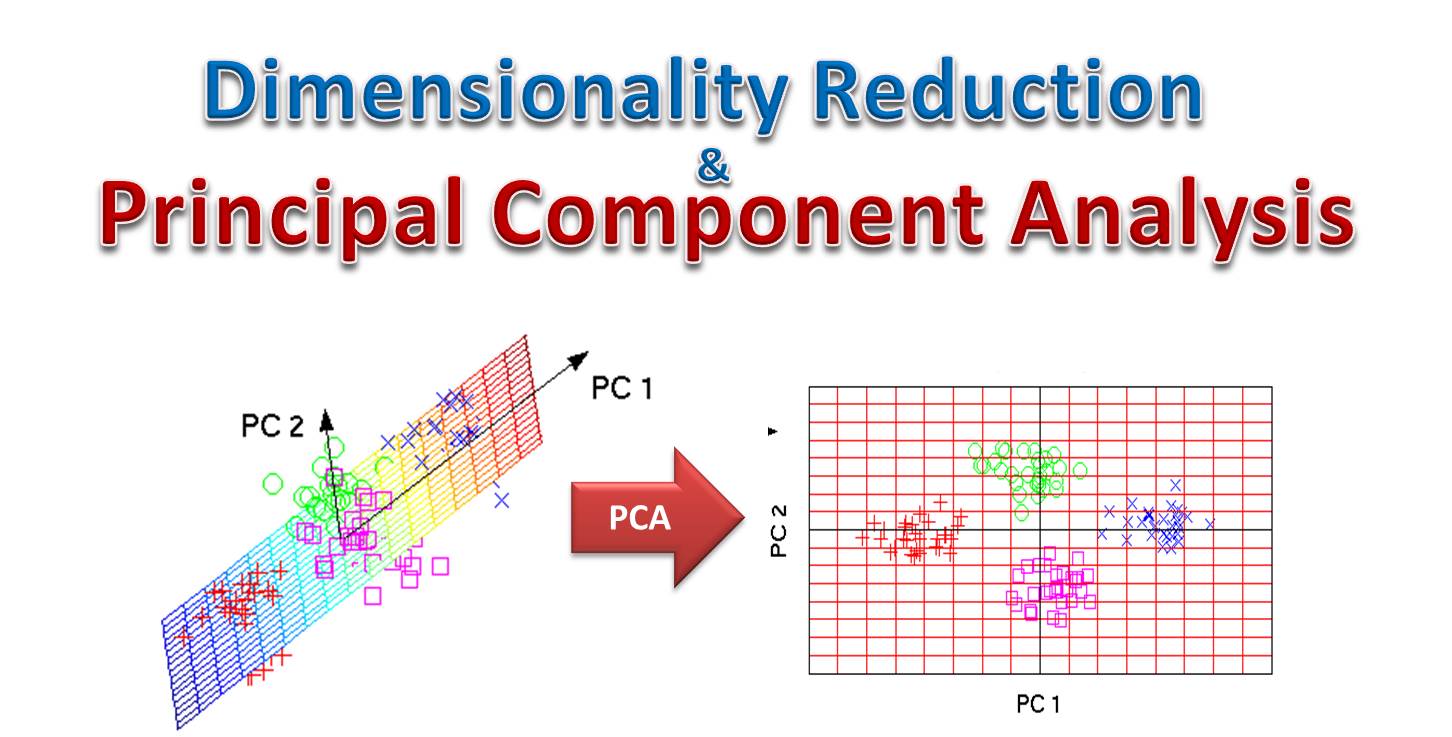
(B) 決策樹可以用於分類和迴歸,是監督式學習。
(C) 邏輯迴歸雖然名為迴歸,但主要用於二元分類問題,是監督式學習。
(D) 主成分分析 (PCA) 是一種常用的降維技術,它在 沒有標籤的情況下尋找資料的主要變異方向,屬於非監督式學習。
#35
★★
非監督式學習的主要優勢之一是什麼?
答案解析
非監督式學習的最大特點是它不需要人工標記的訓練資料。這使得它可以應用於大量存在的
未標記資料,其主要優勢在於能夠自動地
探索和發現資料內部隱藏的結構、模式或關係,例如找出客戶群體、降低資料維度等。這有助於我們更深入地理解資料。
(A) 預測準確度通常是監督式學習的強項。(C) 訓練速度取決於演算法和資料量,不一定更快。(D) 預測未來數值是迴歸任務,屬於監督式學習。
(A) 預測準確度通常是監督式學習的強項。(C) 訓練速度取決於演算法和資料量,不一定更快。(D) 預測未來數值是迴歸任務,屬於監督式學習。
#36
★★★
什麼是獨熱編碼 (One-Hot Encoding)?
答案解析
獨熱編碼是特徵編碼中處理
無序類別型特徵(即類別之間沒有大小或順序關係,如顏色、國家)的常用方法。它會為每個類別創建一個
新的二元特徵(欄位),如果樣本屬於該類別,則對應特徵的值為 1,否則為
0。例如,如果一個「顏色」特徵有「紅、綠、藍」三個類別,獨熱編碼會將其轉換為三個新的二元特徵:「是紅色」(1或0)、「是綠色」(1或0)、「是藍色」(1或0)。這樣可以避免模型錯誤地假設類別之間存在順序關係。
(A) 獨熱編碼通常會增加資料維度。(C) 標準化/縮放是處理數值特徵的方法。(D) 處理缺失值有插補、刪除等方法。
(A) 獨熱編碼通常會增加資料維度。(C) 標準化/縮放是處理數值特徵的方法。(D) 處理缺失值有插補、刪除等方法。
#37
★★★
測試集 (Test Set) 在機器學習流程中的作用是什麼?
答案解析
測試集是在模型開發的最後階段使用,其目的是提供一個
無偏的評估,衡量模型在實際應用中處理全新、未見過數據時的表現如何,即模型的
泛化能力。重要的是,測試集絕對不能用於訓練模型的參數或調整超參數,否則評估結果將會過於樂觀且失去意義。
(A) 是訓練集的作用。(B) 是驗證集的作用。(D) 異常值檢測可以在資料預處理階段進行。
(A) 是訓練集的作用。(B) 是驗證集的作用。(D) 異常值檢測可以在資料預處理階段進行。
#38
★★★
下列哪項最不可能是導致機器學習模型欠擬合的原因?
答案解析
欠擬合通常發生在模型無法捕捉資料的複雜性時。
(A) 模型過於簡單是欠擬合的主要原因。
(B) 如果提供的特徵無法充分描述問題,模型自然難以學習。
(C) 訓練不足會導致模型未能充分學習資料模式。
(D) 使用過多的訓練資料通常有助於提高模型的泛化能力, 更可能防止過擬合,而不太可能導致欠擬合。相反,訓練資料太少更容易導致欠擬合或過擬合。
(A) 模型過於簡單是欠擬合的主要原因。
(B) 如果提供的特徵無法充分描述問題,模型自然難以學習。
(C) 訓練不足會導致模型未能充分學習資料模式。
(D) 使用過多的訓練資料通常有助於提高模型的泛化能力, 更可能防止過擬合,而不太可能導致欠擬合。相反,訓練資料太少更容易導致欠擬合或過擬合。
#39
★★★★
在分類任務中,如果我們更關心被預測為正例的樣本的
準確性(例如:垃圾郵件檢測中,被標記為垃圾郵件的確實是垃圾郵件),應該關注哪個評估指標?
答案解析
* 精確率 (Precision) 衡量的是所有被模型預測為正例的樣本中,有多少是真正為正例。計算公式為:TP / (TP
+ FP)。
當我們不希望將負例錯誤地預測為正例(即最小化偽陽性 FP)時, 精確率是一個重要的指標。例如,在垃圾郵件檢測中,我們不希望將重要的正常郵件(負例)錯誤地標記為垃圾郵件(正例),這時高精確率就很重要。
* 召回率關心的是找出所有實際為正例的能力。
* 準確率是整體正確率。
* F1分數是精確率和召回率的調和平均。
當我們不希望將負例錯誤地預測為正例(即最小化偽陽性 FP)時, 精確率是一個重要的指標。例如,在垃圾郵件檢測中,我們不希望將重要的正常郵件(負例)錯誤地標記為垃圾郵件(正例),這時高精確率就很重要。
* 召回率關心的是找出所有實際為正例的能力。
* 準確率是整體正確率。
* F1分數是精確率和召回率的調和平均。
#40
★★★★
在機器學習中,「模型 (Model)」指的是什麼?
答案解析
機器學習的目標是讓電腦從資料中學習。模型就是這個
學習過程的產物。它是一個數學函數或表示,捕捉了訓練資料中存在的
模式、關係或結構。一旦模型訓練完成,就可以用它來對新的、未見過的資料進行預測(如預測房價、分類郵件)或做出
決策(如推薦商品)。
(A) 資料集是學習的來源,不是學習的結果。(B) 演算法是學習的方法或過程,模型是學習的結果。(D) 硬體是執行學習的工具。
(A) 資料集是學習的來源,不是學習的結果。(B) 演算法是學習的方法或過程,模型是學習的結果。(D) 硬體是執行學習的工具。
#41
★★★
決策樹 (Decision Tree) 是一種常用於分類和迴歸的
監督式學習模型,它的基本結構是?
答案解析
決策樹模型的核心是一個樹狀結構,類似於一個流程圖。
* 每個內部節點 (Internal Node) 代表對某個 特徵的測試(例如:「年齡是否大於30歲?」)。
* 每個分支 (Branch) 代表該測試的結果(例如:「是」或「否」)。
* 每個葉節點 (Leaf Node) 代表最終的 預測結果(例如:分類問題中的類別標籤,或迴歸問題中的數值)。
從根節點開始,根據樣本的特徵值沿著分支向下走,最終到達一個葉節點,該葉節點的值即為模型的預測。決策樹模型因其直觀、易於解釋而受到歡迎。
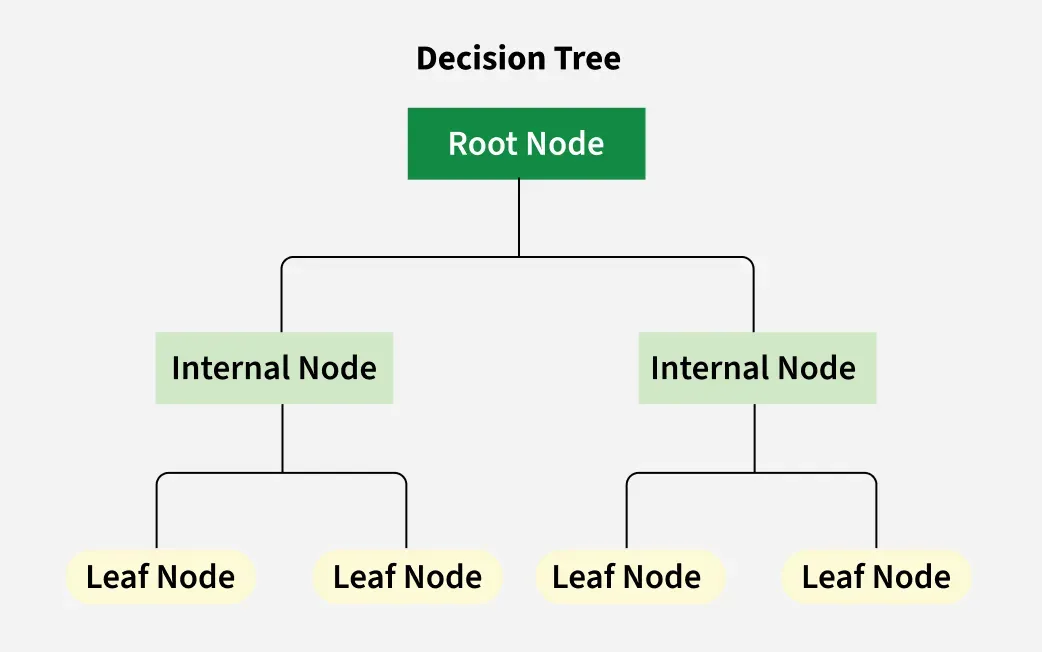
* 每個內部節點 (Internal Node) 代表對某個 特徵的測試(例如:「年齡是否大於30歲?」)。
* 每個分支 (Branch) 代表該測試的結果(例如:「是」或「否」)。
* 每個葉節點 (Leaf Node) 代表最終的 預測結果(例如:分類問題中的類別標籤,或迴歸問題中的數值)。
從根節點開始,根據樣本的特徵值沿著分支向下走,最終到達一個葉節點,該葉節點的值即為模型的預測。決策樹模型因其直觀、易於解釋而受到歡迎。
#42
★★
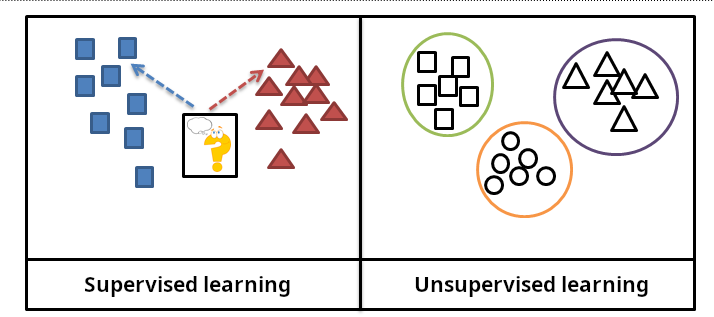
非監督式學習與監督式學習最主要的區別在於訓練資料是否包含?
答案解析
監督式學習和非監督式學習是機器學習的兩種主要範式,其
最根本的區別在於訓練資料的性質。
* 監督式學習:使用帶有標籤的資料進行訓練,即每個輸入樣本都有一個已知的、正確的 輸出標籤。模型學習從輸入到輸出的映射關係。
* 非監督式學習:使用沒有標籤的資料進行訓練。模型需要自己從資料中發現潛在的結構、模式或關係。
因此,訓練資料是否包含輸出標籤是區分兩者的關鍵。
* 監督式學習:使用帶有標籤的資料進行訓練,即每個輸入樣本都有一個已知的、正確的 輸出標籤。模型學習從輸入到輸出的映射關係。
* 非監督式學習:使用沒有標籤的資料進行訓練。模型需要自己從資料中發現潛在的結構、模式或關係。
因此,訓練資料是否包含輸出標籤是區分兩者的關鍵。
#43
★★★
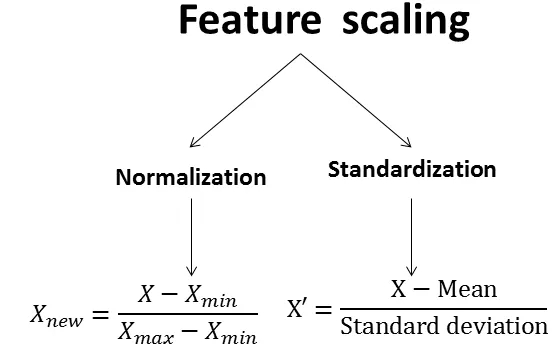
在機器學習中,處理數值範圍差異很大的特徵時,常用的預處理步驟是?
答案解析
當資料集中的不同數值特徵具有非常不同的數值範圍時(例如:年齡範圍可能是 0-100,而收入範圍可能是
0-1,000,000),一些機器學習演算法(特別是基於距離計算的,如 K-近鄰,或使用梯度下降優化的,如線性迴歸、神經網路)可能會對數值範圍較大的特徵給予過多的權重。
特徵縮放或標準化是將這些特徵調整到 相似範圍的過程,以確保所有特徵對模型的貢獻更加均衡。常見方法包括:
* 最小-最大縮放 (Min-Max Scaling): 將值縮放到 [0, 1] 或 [-1, 1] 區間。
* 標準化 (Standardization) / Z-score 標準化: 將資料轉換為平均值為 0,標準差為 1 的分佈。
(A) 用於類別特徵。(C) 用於減少特徵數量。(D) 處理缺失資料。
特徵縮放或標準化是將這些特徵調整到 相似範圍的過程,以確保所有特徵對模型的貢獻更加均衡。常見方法包括:
* 最小-最大縮放 (Min-Max Scaling): 將值縮放到 [0, 1] 或 [-1, 1] 區間。
* 標準化 (Standardization) / Z-score 標準化: 將資料轉換為平均值為 0,標準差為 1 的分佈。
(A) 用於類別特徵。(C) 用於減少特徵數量。(D) 處理缺失資料。
#44
★★
為什麼在評估模型性能時,通常不只看單一指標 (例如準確率),而是會綜合考慮多個指標 (例如精確率、召回率、
F1分數)?
答案解析
單一的評估指標,如準確率,有時可能會產生誤導,尤其是在以下情況:
* 資料不平衡:當不同類別的樣本數量差異很大時,準確率會被多數類別主導。
* 不同錯誤的代價不同:在某些應用中,偽陽性和偽陰性錯誤的後果可能非常不同(例如醫療診斷)。
因此,需要根據具體的應用需求,綜合考慮精確率(關注預測為正的準確性)、召回率(關注找出所有正例的能力)、 F1分數(兩者的平衡)等多個指標,才能更全面、更準確地評估模型的性能。
* 資料不平衡:當不同類別的樣本數量差異很大時,準確率會被多數類別主導。
* 不同錯誤的代價不同:在某些應用中,偽陽性和偽陰性錯誤的後果可能非常不同(例如醫療診斷)。
因此,需要根據具體的應用需求,綜合考慮精確率(關注預測為正的準確性)、召回率(關注找出所有正例的能力)、 F1分數(兩者的平衡)等多個指標,才能更全面、更準確地評估模型的性能。
#45
★★★
「早期停止」(Early Stopping) 是一種用於防止過擬合的技術,其基本原理是?
答案解析
早期停止是一種簡單而有效的正則化方法,用於防止
過擬合。其原理是在模型訓練的每個週期(epoch)或一定迭代次數後,使用獨立的驗證集來評估模型的性能(例如:驗證誤差或驗證準確率)。
當驗證集上的性能不再顯著提升,甚至開始變差時,即使訓練集上的性能仍在提高,也
提前終止訓練過程。這樣可以防止模型過度學習訓練資料中的雜訊,從而獲得更好的泛化能力。
(B) 只看訓練誤差可能導致過擬合。(D) 達到100%訓練準確率通常是嚴重過擬合的標誌。
(B) 只看訓練誤差可能導致過擬合。(D) 達到100%訓練準確率通常是嚴重過擬合的標誌。
#46
★
哪位科學家被廣泛認為是人工智慧 (AI) 領域的奠基人之一,並提出了著名的「圖靈測試」(
Turing Test)?
答案解析
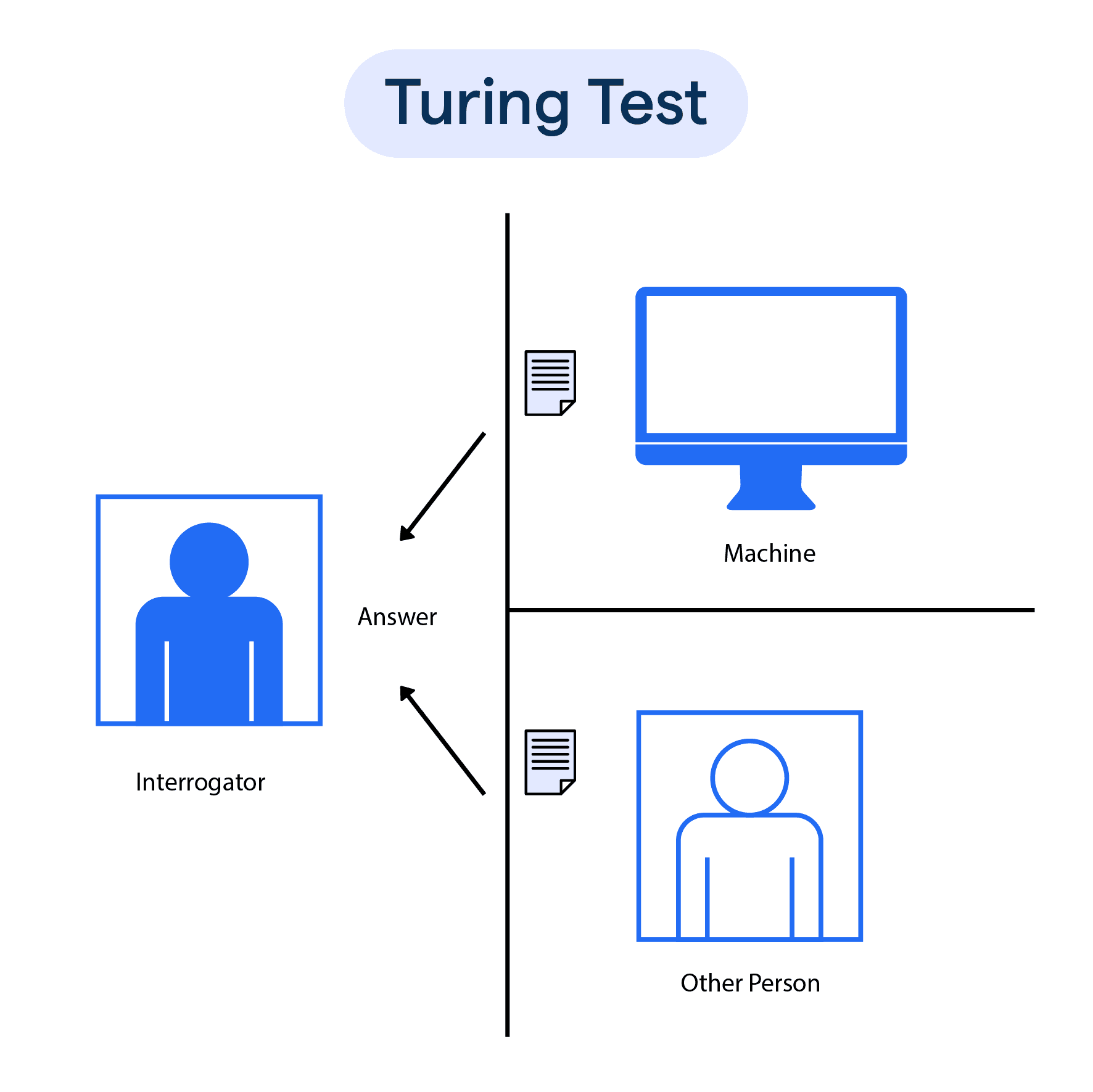
艾倫·圖靈 (Alan Turing) 是一位英國數學家、邏輯學家和密碼學家,被譽為計算機科學與人工智慧之父。他在 1950
年發表的論文《計算機器與智能》中探討了機器是否能思考的問題,並提出了一種判斷機器是否具有智能的測試方法,即「
圖靈測試」。該測試建議,如果一個人(裁判)在與一個機器和一個人類進行文字對話時,無法區分哪個是機器,哪個是人類,那麼就可以認為該機器具有智能。
#47
★★
監督式學習中的邏輯迴歸 (Logistic Regression) 通常用於解決什麼問題?
答案解析
雖然名稱中帶有「迴歸」,但邏輯迴歸實際上是一種廣泛應用於二元分類問題的監督式學習演算法。它透過一個
邏輯函數(通常是 Sigmoid 函數)將線性迴歸的輸出映射到 (0, 1) 區間,表示屬於某個類別的
機率。然後根據這個機率值(例如:大於0.5則判斷為正例)來進行分類。
(B) 預測連續值是線性迴歸等演算法的任務。(C) 分群是非監督式學習。(D) 是強化學習的目標。
(B) 預測連續值是線性迴歸等演算法的任務。(C) 分群是非監督式學習。(D) 是強化學習的目標。

#48
★
關聯規則學習 (Association Rule Learning),例如找出「購買了麵包的顧客也很可能購買牛奶」這樣的規則,屬於哪一類機器學習?
答案解析
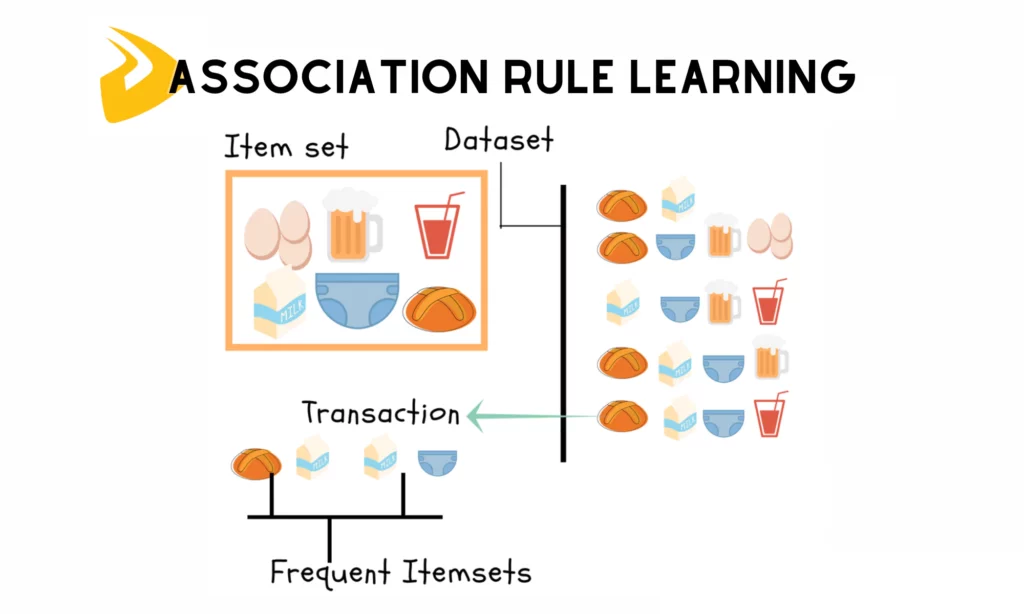
關聯規則學習(例如著名的Apriori演算法)的目標是從大型資料集中
發現項集之間有趣的關聯或相關性。例如,在購物籃分析中找出哪些商品經常被一起購買。這個過程並
不需要預先定義的標籤,而是直接從資料本身探索模式,因此屬於非監督式學習的範疇。
#49
★★
在機器學習中,"髒數據" (Dirty Data) 通常指的是什麼?
答案解析
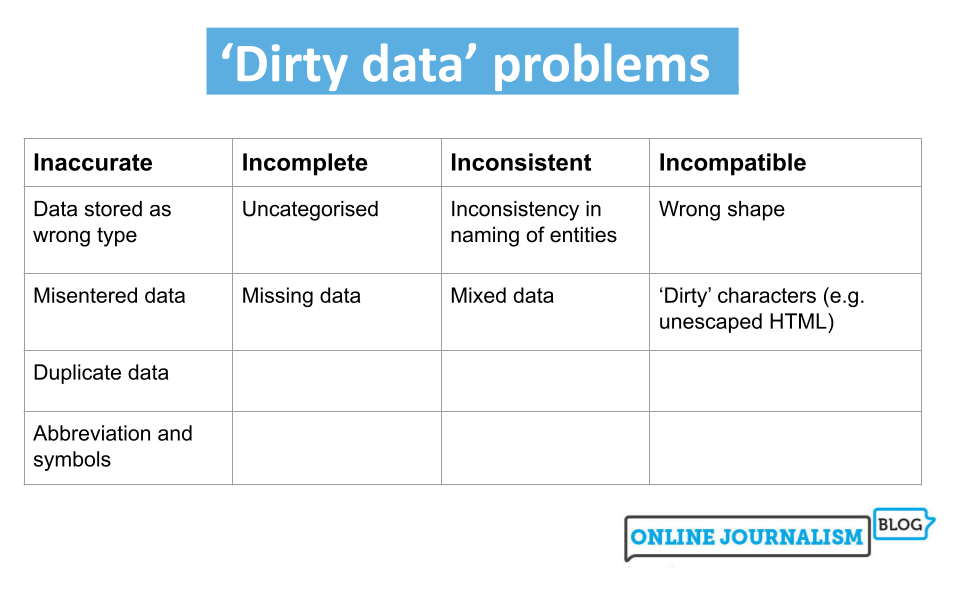
"髒數據" 是對品質不佳的資料的通稱。這些資料可能因為各種原因而存在問題,例如:
* 錯誤:資料記錄不準確(例如:年齡為負數)。
* 不一致:相同意義的資料有多種表示方式(例如:"台北市" vs "臺北市")。
* 缺失值:資料欄位為空。
* 格式不正確:資料不符合預期的格式(例如:日期格式混亂)。
使用髒數據訓練模型會導致結果不可靠,因此資料清理是資料預處理的重要步驟。
* 錯誤:資料記錄不準確(例如:年齡為負數)。
* 不一致:相同意義的資料有多種表示方式(例如:"台北市" vs "臺北市")。
* 缺失值:資料欄位為空。
* 格式不正確:資料不符合預期的格式(例如:日期格式混亂)。
使用髒數據訓練模型會導致結果不可靠,因此資料清理是資料預處理的重要步驟。
#50
★★
當資料量非常有限時,哪種模型評估技術特別有用,可以更充分地利用所有資料?
答案解析
當可用的資料量非常有限時,如果進行簡單的訓練/測試集劃分(例如:80%訓練,20%測試),可能會導致
訓練集過小無法充分訓練模型,或者測試集過小導致評估結果不穩定、偶然性高。
交叉驗證(特別是 K-摺交叉驗證)通過將資料輪流用於訓練和驗證,讓 每個資料點都有機會被用於驗證,同時也保證了大部分資料能用於訓練。這樣可以更 充分地利用有限的資料,得到更穩定和可靠的模型性能評估。
(A) 只用訓練集評估會導致過擬合的誤判。(B) 簡單劃分在小數據集上效果不佳。(D) 測試集不能用於訓練或調優過程中的評估。
交叉驗證(特別是 K-摺交叉驗證)通過將資料輪流用於訓練和驗證,讓 每個資料點都有機會被用於驗證,同時也保證了大部分資料能用於訓練。這樣可以更 充分地利用有限的資料,得到更穩定和可靠的模型性能評估。
(A) 只用訓練集評估會導致過擬合的誤判。(B) 簡單劃分在小數據集上效果不佳。(D) 測試集不能用於訓練或調優過程中的評估。
#51
★★
如果一個機器學習模型的偏差 (Bias) 很高,通常意味著什麼?
答案解析
偏差衡量的是模型的預測值與實際值之間的系統性差異。高偏差通常意味著模型
未能捕捉到資料中的基本模式或趨勢,即模型過於簡單,無法很好地擬合資料。這種情況就是
欠擬合。
(B) 高變異數通常與模型過於複雜和過擬合相關。(C) 高偏差通常伴隨低變異數。(D) 高偏差模型在訓練集上表現通常也不好。
(B) 高變異數通常與模型過於複雜和過擬合相關。(C) 高偏差通常伴隨低變異數。(D) 高偏差模型在訓練集上表現通常也不好。
#52
★★★
評估迴歸模型時,決定係數 (R-squared, R²) 的值接近 1 通常表示什麼?
答案解析
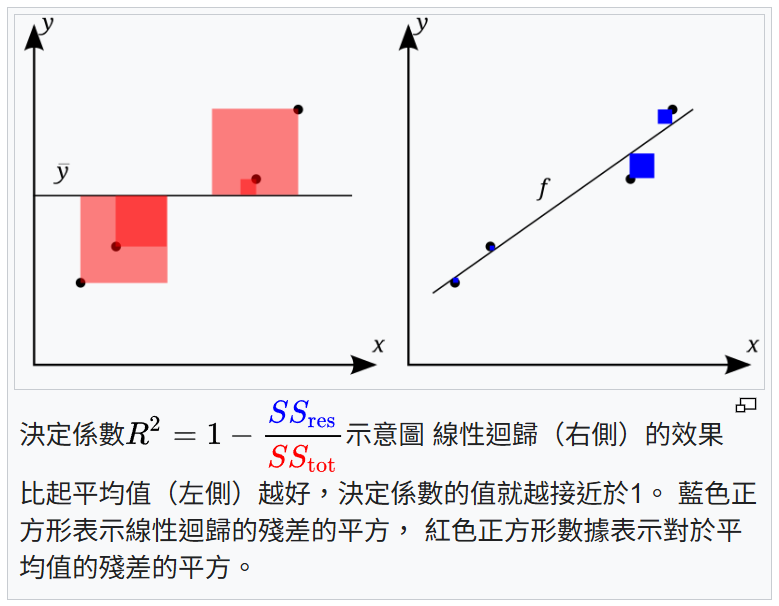
決定係數 (R²) 是評估迴歸模型擬合優度的指標,其值範圍通常在 0 到 1
之間。它表示模型解釋的目標變數(依變數)總變異性的比例。
* R² 接近 1:表示模型的自變數能夠解釋目標變數大部分的變異,模型擬合得較好。
* R² 接近 0:表示模型無法解釋目標變數的變異。
需要注意的是,高 R² 不一定代表模型就是好的,它也可能表示模型過擬合。因此需要結合其他指標和驗證方法來綜合評估。但 R² 接近 1 的基本含義是模型對資料變異性的解釋度高。
* R² 接近 1:表示模型的自變數能夠解釋目標變數大部分的變異,模型擬合得較好。
* R² 接近 0:表示模型無法解釋目標變數的變異。
需要注意的是,高 R² 不一定代表模型就是好的,它也可能表示模型過擬合。因此需要結合其他指標和驗證方法來綜合評估。但 R² 接近 1 的基本含義是模型對資料變異性的解釋度高。
#53
★★★
機器學習模型訓練完成後,進行「推論」(Inference) 指的是什麼過程?
答案解析
機器學習的生命週期通常分為兩個主要階段:訓練 (Training) 和
推論 (Inference)。
* 訓練:使用已有的資料集來學習模型參數的過程。
* 推論:將已經訓練完成的模型部署到實際應用中,用於處理 新的、未標記的輸入資料,並產生預測、分類或其他結果的過程。這個過程也稱為預測 ( Prediction)。
* 訓練:使用已有的資料集來學習模型參數的過程。
* 推論:將已經訓練完成的模型部署到實際應用中,用於處理 新的、未標記的輸入資料,並產生預測、分類或其他結果的過程。這個過程也稱為預測 ( Prediction)。
#54
★★
在機器學習中,處理缺失值 (Missing Values) 的方法
不包括下列哪一項?
答案解析
處理缺失值是資料預處理的重要步驟,常見方法有:
* 刪除:如果缺失值比例很小,或某個特徵/樣本大部分都是缺失值,可以考慮直接刪除。
* 插補:用某個值來填補缺失值,例如用該特徵的平均值(適用於數值)、 中位數(適用於偏態數值)或眾數(適用於類別)。
* 模型預測:使用其他特徵訓練一個模型來預測缺失值。
(D) 將所有缺失值簡單地替換為零可能引入偏差,因為 0 本身可能是一個有意義的數值,或者會扭曲資料的分佈,通常不是一個好的通用方法(除非 0 在該特徵中有特殊含義且適合填補)。
* 刪除:如果缺失值比例很小,或某個特徵/樣本大部分都是缺失值,可以考慮直接刪除。
* 插補:用某個值來填補缺失值,例如用該特徵的平均值(適用於數值)、 中位數(適用於偏態數值)或眾數(適用於類別)。
* 模型預測:使用其他特徵訓練一個模型來預測缺失值。
(D) 將所有缺失值簡單地替換為零可能引入偏差,因為 0 本身可能是一個有意義的數值,或者會扭曲資料的分佈,通常不是一個好的通用方法(除非 0 在該特徵中有特殊含義且適合填補)。
#55
★★
「資料洩漏」(Data Leakage) 在機器學習中指的是什麼情況?
答案解析
資料洩漏是指在模型訓練時,使用了在實際預測時無法獲得的資訊。這種資訊可能直接或間接地來自
測試集,或者是與預測目標緊密相關但在預測時點尚不可知的未來資訊。資料洩漏會導致模型在
驗證集或測試集上表現異常地好
,給人一種模型性能優越的假象,但實際部署後性能會急劇下降。例如,在預測使用者是否購買某商品時,如果訓練資料中包含了該使用者最終是否購買的資訊(來自未來的資訊),就會發生資料洩漏。
(A) 指的是資料安全問題。(C) 指的是模型輸出的隱私問題。(D) 是資源問題。
(A) 指的是資料安全問題。(C) 指的是模型輸出的隱私問題。(D) 是資源問題。
#56
★★★★
為了避免過擬合,除了正則化和早期停止外,下列哪項也是常用的方法?
答案解析
過擬合的根本原因之一是模型從有限的訓練資料中學到了過多的噪音和細節。因此,
增加更多、更多樣化的訓練資料是
最有效的防止過擬合的方法之一。更多的資料可以幫助模型學習到更具代表性和泛化能力的模式,減少對特定訓練樣本噪音的依賴。
(A) 更小的訓練集更容易導致過擬合。(B) 增加層數通常會增加模型複雜度,可能加劇過擬合。(D) 移除驗證集會失去監控過擬合的手段。
(A) 更小的訓練集更容易導致過擬合。(B) 增加層數通常會增加模型複雜度,可能加劇過擬合。(D) 移除驗證集會失去監控過擬合的手段。
#57
★★
機器學習模型的泛化能力 (Generalization Ability) 指的是什麼?
答案解析
機器學習的最終目標不是讓模型完美地記住訓練資料,而是要讓模型能夠從訓練資料中學習到通用的模式,並將這些模式應用於
新的、從未見過的資料上,做出準確的預測或判斷。這種模型對新資料的適應能力和預測能力就稱為
泛化能力。泛化能力差的模型可能存在過擬合或欠擬合的問題。
#58
★
深度學習 (Deep Learning) 是機器學習的一個分支,它主要使用哪種類型的模型結構?
答案解析
深度學習是機器學習的一個子領域,其核心是使用深度人工神經網路(即包含
多個處理層,通常指多個
隱藏層)來學習資料的複雜表示。這些深層結構使得模型能夠從原始資料中逐層提取和學習從低階到高階的抽象特徵,從而在圖像識別、自然語言處理等複雜任務中取得突破性進展。
(A), (B), (D) 屬於傳統(或稱為淺層)機器學習演算法。
(A), (B), (D) 屬於傳統(或稱為淺層)機器學習演算法。
#59
★
在機器學習中,資料集 (Dataset) 指的是什麼?
答案解析
資料集是機器學習的基礎,它是由多筆資料記錄(也稱為樣本、實例或觀察值)組成的
集合。每一筆記錄通常包含多個特徵(描述該記錄的屬性)以及可能的
標籤(目標輸出)。資料集被用來訓練模型學習模式,以及
評估模型訓練後的效果。
#60
★
將機器學習模型從開發環境轉移到實際應用環境(例如網站或手機APP)供使用者使用的過程,稱為什麼?
答案解析
模型部署是將訓練和評估完成的機器學習模型整合到
生產環境中,使其能夠接收真實世界的輸入數據並提供預測或服務的過程。這可能涉及將模型封裝成
API、整合到現有應用程式或部署到雲端平台等步驟。部署是讓模型產生實際價值的關鍵環節。
#61
★★
如果一個機器學習模型的變異數 (Variance) 很高,通常意味著什麼?
答案解析
變異數衡量的是模型對於不同訓練資料集的預測結果的變化程度。高變異數意味著模型對訓練資料的
隨機性或雜訊非常敏感,如果在不同的訓練資料子集上訓練,模型可能會產生非常不同的結果。這通常發生在模型
過於複雜,學習了訓練資料中太多的細節和雜訊時,即過擬合。
(A) 高偏差通常與模型太簡單和欠擬合相關。(C) 高變異數通常伴隨低偏差。(D) 高變異數模型(過擬合)通常在測試集上表現不佳。
(A) 高偏差通常與模型太簡單和欠擬合相關。(C) 高變異數通常伴隨低偏差。(D) 高變異數模型(過擬合)通常在測試集上表現不佳。
#62
★★★
在二元分類問題中,ROC曲線 (Receiver Operating Characteristic Curve) 描繪的是哪兩個指標之間的關係?
答案解析
ROC曲線是一種用於評估和視覺化二元分類模型性能的圖形工具。它以偽陽性率 (
FPR = FP / (FP + TN)) 為橫軸,以真陽性率 (
TPR,即召回率 Recall = TP / (TP + FN)) 為
縱軸,繪製出模型在不同分類閾值下的表現。曲線越靠近左上角,表示模型性能越好。
(A) PR曲線描繪的是精確率和召回率的關係。
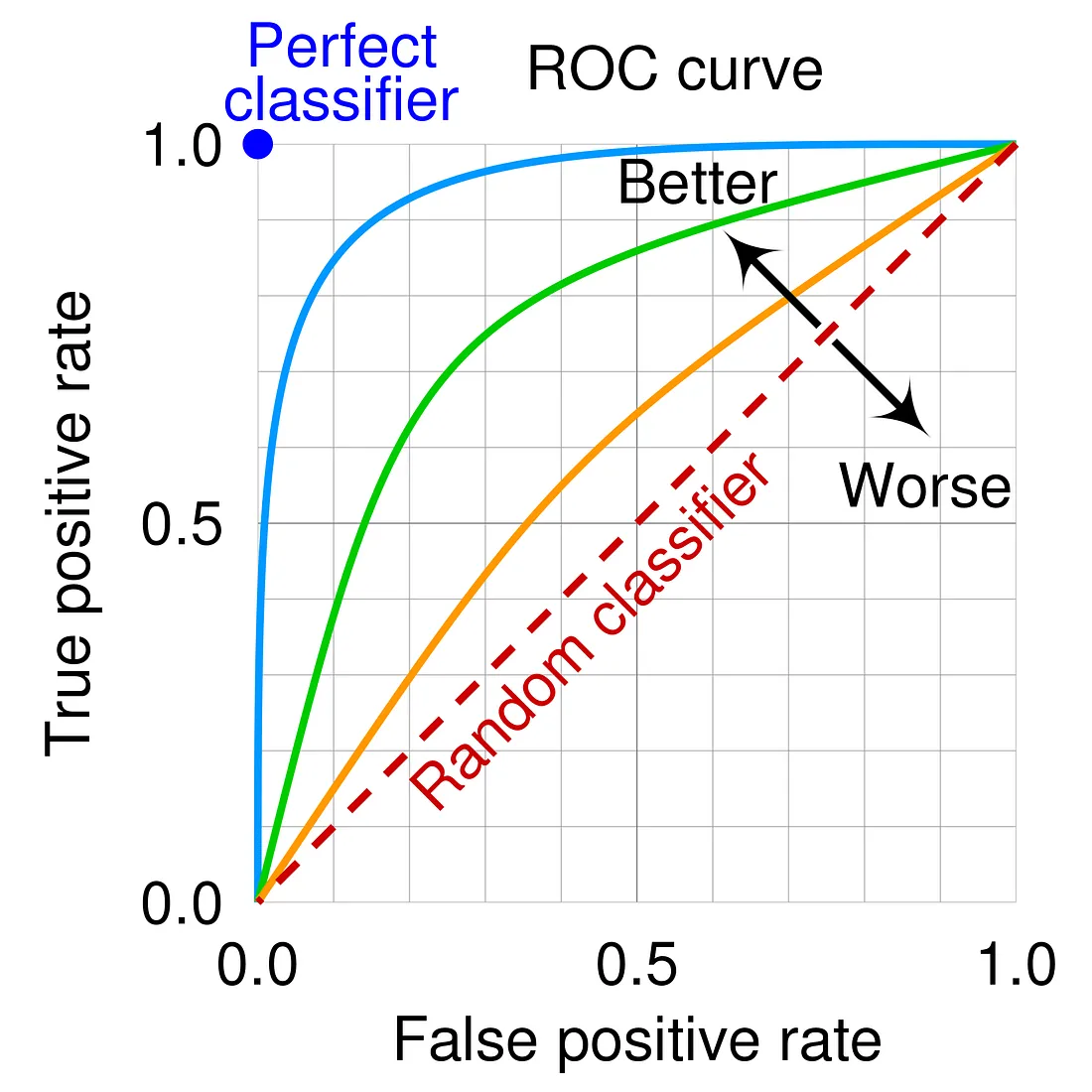
(A) PR曲線描繪的是精確率和召回率的關係。
#63
★★
機器學習與資料探勘 (Data Mining) 的關係通常被描述為?
答案解析
資料探勘是一個更廣泛的概念,指的是從大量資料中
自動或半自動地提取有用資訊和知識的過程。這個過程包含多個步驟,如資料清理、整合、轉換、探勘模式和評估。
機器學習則提供了許多用於在資料探勘過程中發現模式和建立預測模型的演算法和技術。因此,機器學習可以被視為實現資料探勘目標的 核心工具或技術手段之一。
機器學習則提供了許多用於在資料探勘過程中發現模式和建立預測模型的演算法和技術。因此,機器學習可以被視為實現資料探勘目標的 核心工具或技術手段之一。
#64
★★
K-近鄰 (K-Nearest Neighbors, KNN) 演算法是如何進行分類預測的?
答案解析
K-近鄰 (KNN) 是一種簡單直觀的監督式學習演算法,可用於分類和
迴歸。在分類任務中,對於一個新的、未標記的樣本,KNN會:
1. 計算該新樣本與訓練集中所有樣本的距離(常用歐氏距離)。
2. 找出距離該新樣本最近的 K 個訓練樣本。
3. 統計這 K 個近鄰樣本中,哪個類別出現次數最多(多數決)。
4. 將這個多數類別賦予給新樣本作為預測結果。
K 值的選擇對模型性能有影響。
1. 計算該新樣本與訓練集中所有樣本的距離(常用歐氏距離)。
2. 找出距離該新樣本最近的 K 個訓練樣本。
3. 統計這 K 個近鄰樣本中,哪個類別出現次數最多(多數決)。
4. 將這個多數類別賦予給新樣本作為預測結果。
K 值的選擇對模型性能有影響。
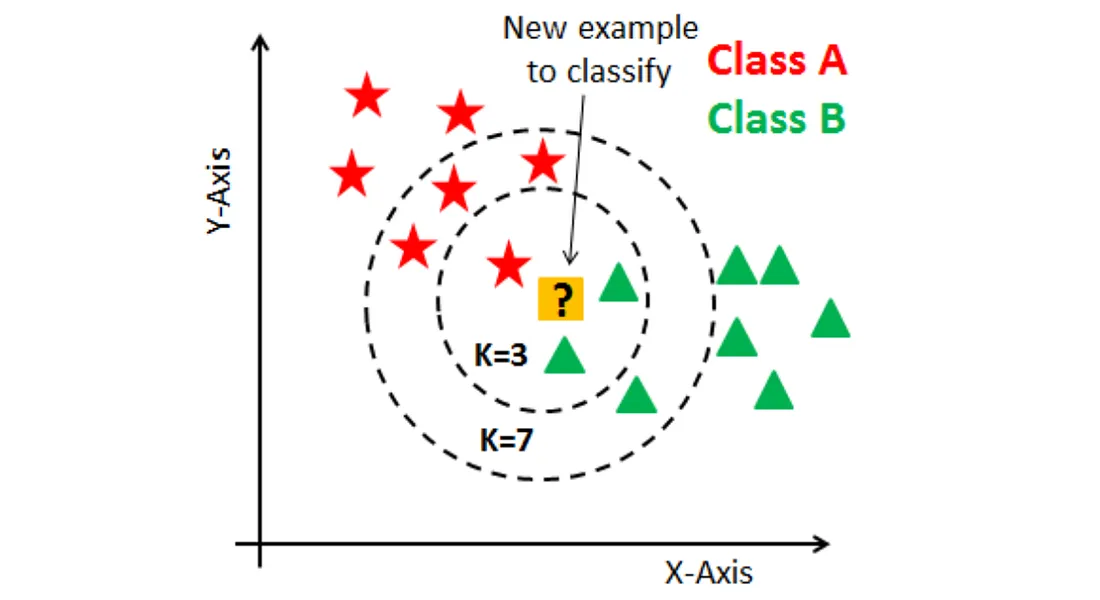
#65
★
AlphaGo 使用強化學習擊敗了世界圍棋冠軍,這體現了強化學習在哪方面的應用潛力?
答案解析
強化學習的核心是學習如何在一個環境中透過試錯來做出最佳的決策序列以獲得最大獎勵。這使得它非常適合應用於需要制定
策略的場景,例如:
* 遊戲 (如圍棋、星海爭霸)
* 機器人控制
* 資源管理
* 自動駕駛中的決策
AlphaGo 的成功正是強化學習在複雜策略遊戲中強大能力的體現。
(A) 分群是非監督式。(B) 預測是監督式。(D) 降維是非監督式。
* 遊戲 (如圍棋、星海爭霸)
* 機器人控制
* 資源管理
* 自動駕駛中的決策
AlphaGo 的成功正是強化學習在複雜策略遊戲中強大能力的體現。
(A) 分群是非監督式。(B) 預測是監督式。(D) 降維是非監督式。
#66
★★
為什麼資料的品質對於機器學習模型至關重要?
答案解析
機器學習的本質是從資料中提取資訊和模式。如果用於訓練模型的資料
品質很差(例如:包含大量錯誤、缺失值、偏差或不相關資訊),那麼模型學習到的模式也將是
錯誤或不可靠的。這會直接導致模型在預測新資料時表現不佳,無法達到預期效果。正如"Garbage in, garbage out"所言,
高品質的資料是成功機器學習專案的基礎。
(A) 品質差的資料可能包含雜訊,反而可能增加訓練難度或時間。(C) 資料品質對所有類型的機器學習都很重要。(D) 演算法無法完全克服低劣資料帶來的問題。
(A) 品質差的資料可能包含雜訊,反而可能增加訓練難度或時間。(C) 資料品質對所有類型的機器學習都很重要。(D) 演算法無法完全克服低劣資料帶來的問題。
#67
★
在典型的訓練/驗證/測試集劃分中,哪個資料集佔的比例通常最大?
答案解析
為了讓模型能夠充分學習資料中的模式,訓練集通常需要包含盡可能多的數據。常見的劃分比例可能是:
* 60% 訓練集, 20% 驗證集, 20% 測試集
* 70% 訓練集, 15% 驗證集, 15% 測試集
* 80% 訓練集, 10% 驗證集, 10% 測試集
雖然沒有絕對固定的比例,但訓練集佔比最大是普遍的做法。驗證集和測試集需要足夠大以提供可靠的評估,但不需要像訓練集那麼大。
* 60% 訓練集, 20% 驗證集, 20% 測試集
* 70% 訓練集, 15% 驗證集, 15% 測試集
* 80% 訓練集, 10% 驗證集, 10% 測試集
雖然沒有絕對固定的比例,但訓練集佔比最大是普遍的做法。驗證集和測試集需要足夠大以提供可靠的評估,但不需要像訓練集那麼大。
#68
★★
下列哪項不是正則化 (Regularization) 的主要目的?
答案解析
正則化是一種向模型引入額外限制(通常是懲罰模型參數的複雜性)的技術。其主要目的是
防止模型過度擬合訓練資料,從而降低模型的變異數,並
提高其在未見過資料上的泛化能力。
(D) 正則化實際上是透過限制模型複雜度來 略微犧牲模型在訓練集上的擬合程度,以換取更好的泛化性能,而不是提高訓練集擬合程度。
(D) 正則化實際上是透過限制模型複雜度來 略微犧牲模型在訓練集上的擬合程度,以換取更好的泛化性能,而不是提高訓練集擬合程度。
#69
★★★
在二元分類中,F1分數 (F1-Score) 是哪兩個指標的調和平均數?
答案解析
F1分數是精確率 (Precision) 和召回率 (Recall) 的
調和平均數,計算公式為:F1 = 2 * (Precision * Recall) / (Precision + Recall)。
它試圖在精確率和召回率之間取得平衡。當兩者都很重要時,F1分數是一個很好的綜合評估指標。特別是在 資料不平衡的情況下,F1分數通常比準確率更能反映模型的真實性能。
它試圖在精確率和召回率之間取得平衡。當兩者都很重要時,F1分數是一個很好的綜合評估指標。特別是在 資料不平衡的情況下,F1分數通常比準確率更能反映模型的真實性能。
#70
★
機器學習通常被認為是哪個更廣泛領域的一個子集?
答案解析
人工智慧 (AI) 是一個廣泛的領域,旨在創造能夠模仿人類智能行為的機器或系統。
機器學習 (ML) 是實現人工智慧的一種主要方法或途徑,它專注於開發能夠讓機器從資料中
自動學習的演算法。而深度學習 (Deep Learning, DL)
又是機器學習的一個更深層次的分支,使用深度神經網路。因此,關係通常被理解為:AI > ML > DL。
統計學為機器學習提供了很多理論基礎和方法,但機器學習更側重於預測和自動化。
統計學為機器學習提供了很多理論基礎和方法,但機器學習更側重於預測和自動化。
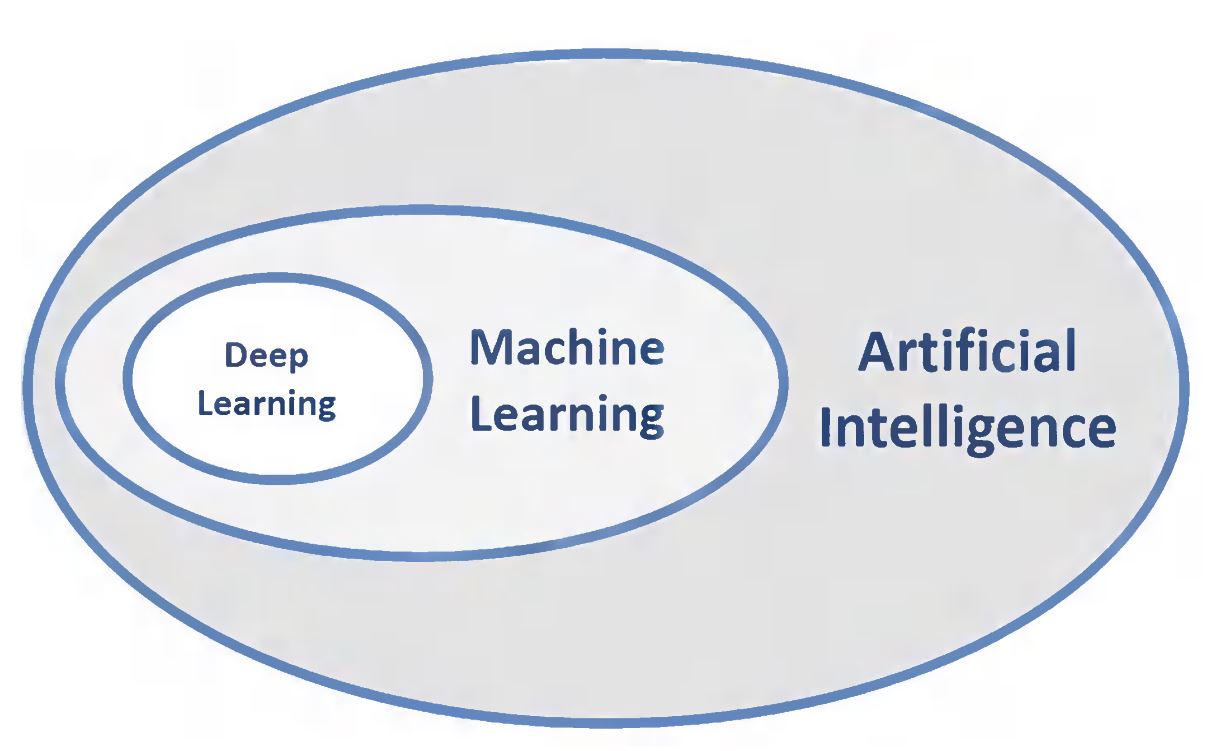
#71
★
在監督式學習中,"ground truth" 通常指的是什麼?
答案解析
"Ground truth"(地面實況/真實標籤)在監督式學習的語境下,指的是
訓練資料中每個輸入樣本對應的、已知的、客觀真實的正確答案或標籤。模型在訓練過程中會將自己的預測結果與 ground truth
進行比較,計算損失函數,並據此調整參數以學習如何更接近 ground truth。
#72
★★
哪種機器學習方法在處理異常檢測 (Anomaly Detection)
問題時特別有用,尤其是當正常行為模式已知,但異常模式未知或多樣時?
答案解析
異常檢測
的目標是識別出與大多數資料顯著不同的資料點(異常值)。在許多實際情況下,我們可能擁有大量"正常"行為的資料,但"異常"行為的資料很少,或者異常的模式事先未知且多種多樣,難以標記。
在這種情況下,非監督式學習方法(如分群、基於密度的方法、或降維後看距離)非常有用。它們可以 學習正常資料的模式或分佈,然後將那些 偏離正常模式太遠的資料點識別為異常。監督式學習需要大量標記好的異常樣本,這通常難以獲得。
在這種情況下,非監督式學習方法(如分群、基於密度的方法、或降維後看距離)非常有用。它們可以 學習正常資料的模式或分佈,然後將那些 偏離正常模式太遠的資料點識別為異常。監督式學習需要大量標記好的異常樣本,這通常難以獲得。
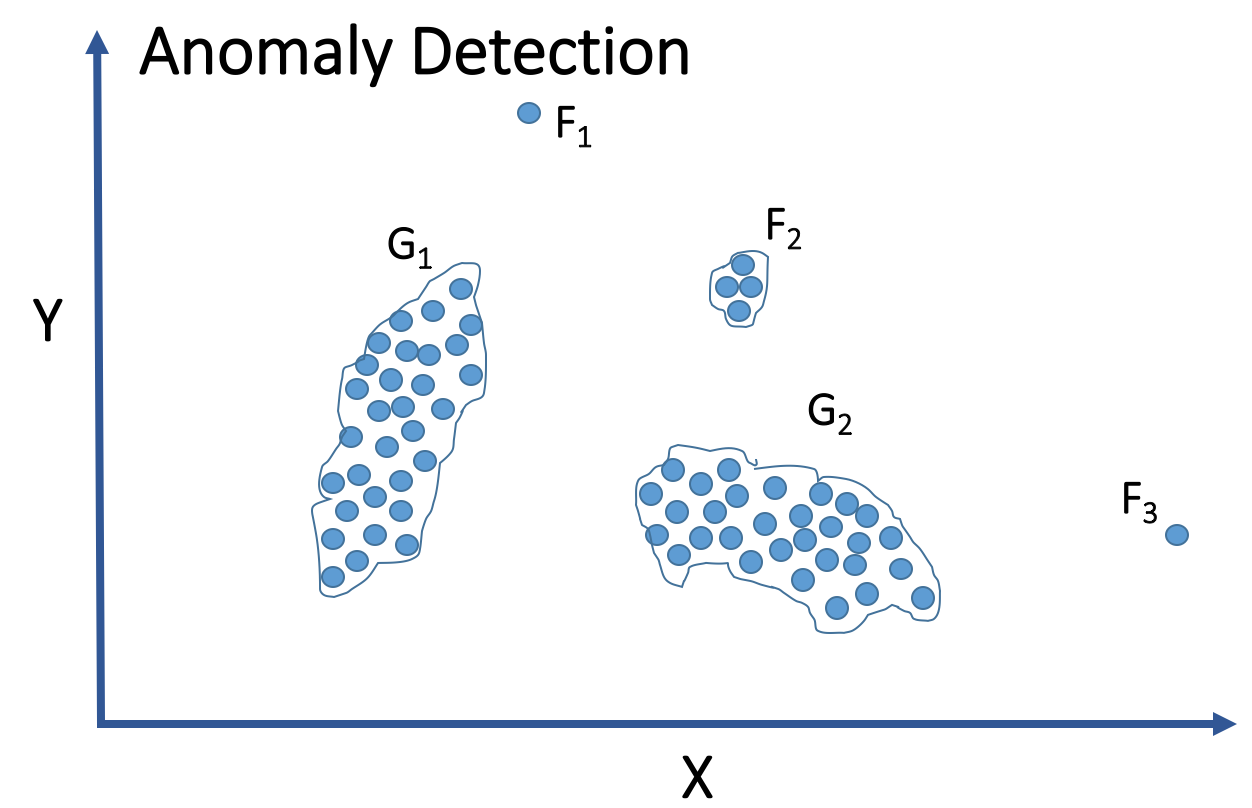
#73
★★
數值型資料和類別型資料是機器學習中常見的資料類型,下列何者屬於類別型資料 (Categorical Data)?
答案解析
* 數值型資料 (Numerical Data): 表示數量或
測量值,可以是連續的(如身高、溫度)或離散的(如房間數量)。
* 類別型資料 (Categorical Data): 表示將事物 歸入不同的組別或類別,這些類別通常沒有內在的數量意義。例如:顏色、品牌、性別、國家。
(A), (B), (D) 都是可以測量的數值。(C) 汽車品牌是將汽車歸類的名稱,屬於類別型資料。
* 類別型資料 (Categorical Data): 表示將事物 歸入不同的組別或類別,這些類別通常沒有內在的數量意義。例如:顏色、品牌、性別、國家。
(A), (B), (D) 都是可以測量的數值。(C) 汽車品牌是將汽車歸類的名稱,屬於類別型資料。
#74
★
模型訓練過程中的迭代 (Iteration) 或週期 (Epoch)
指的是什麼?
答案解析
在許多機器學習演算法(尤其是使用梯度下降等優化方法的演算法)的訓練過程中,模型需要反覆處理訓練資料來逐步調整參數和學習模式。
* 迭代 (Iteration): 通常指模型處理一個批次 ( Batch) 的資料並更新一次參數的過程。
* 週期 (Epoch): 指模型完整地處理過一次整個訓練資料集。一個週期包含多次迭代。
訓練通常需要經過多個週期才能達到較好的效果。
* 迭代 (Iteration): 通常指模型處理一個批次 ( Batch) 的資料並更新一次參數的過程。
* 週期 (Epoch): 指模型完整地處理過一次整個訓練資料集。一個週期包含多次迭代。
訓練通常需要經過多個週期才能達到較好的效果。
#75
★★
當模型同時具有高偏差和高變異數時,通常表示什麼?
答案解析
* 高偏差意味著模型無法很好地擬合訓練資料(欠擬合)。
* 高變異數意味著模型對訓練資料的變化非常敏感,無法很好地泛化到新資料(過擬合)。
如果一個模型同時具有高偏差和高變異數(雖然理論上較少見,但可能發生在模型選擇或特徵工程極差的情況下),那表示這個模型 既學不好訓練資料,又不能應對新資料,性能通常是非常差的。理想的模型應該是低偏差且低變異數。
* 高變異數意味著模型對訓練資料的變化非常敏感,無法很好地泛化到新資料(過擬合)。
如果一個模型同時具有高偏差和高變異數(雖然理論上較少見,但可能發生在模型選擇或特徵工程極差的情況下),那表示這個模型 既學不好訓練資料,又不能應對新資料,性能通常是非常差的。理想的模型應該是低偏差且低變異數。
#76
★★★
評估迴歸模型時,平均絕對誤差 (MAE, Mean Absolute Error) 比
均方誤差 (MSE) 更不容易受到什麼的影響?
答案解析
均方誤差 (MSE) 計算的是誤差的平方的平均值,而平均絕對誤差 (
MAE) 計算的是誤差的絕對值的平均值。
由於平方運算會放大較大的誤差值,因此 MSE 對於資料中的 離群值(即誤差特別大的點)非常敏感。一個離群值會對 MSE 產生很大的影響。
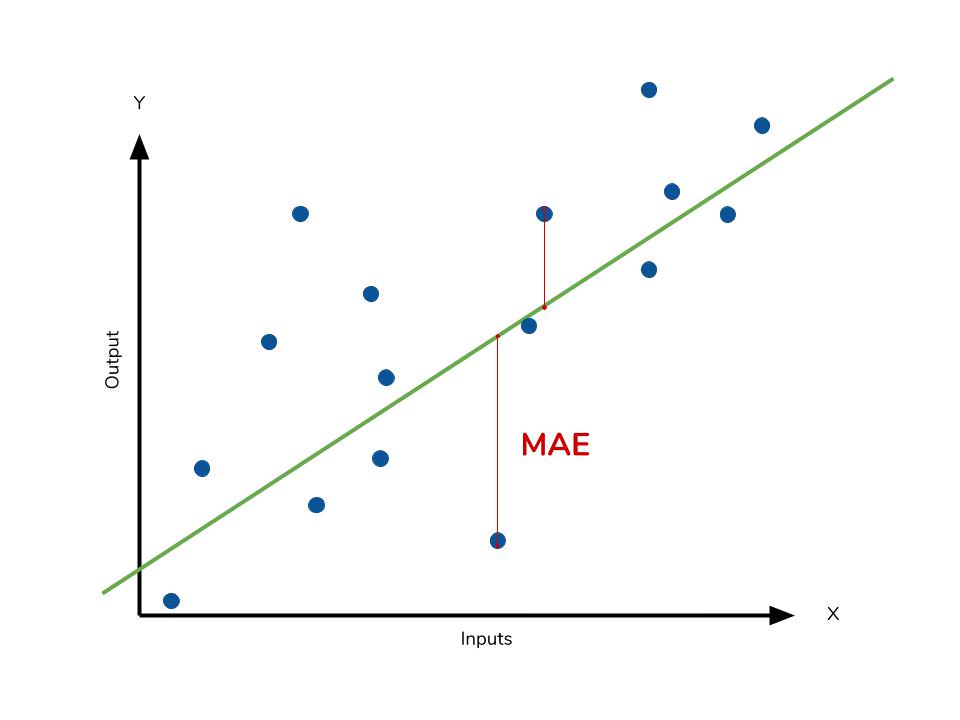
相比之下,MAE 計算的是絕對誤差,對離群值的敏感度較低,更能反映模型在大多數樣本上的平均誤差水平。因此,在存在較多離群值的數據中, MAE 可能是一個更穩健的評估指標。
由於平方運算會放大較大的誤差值,因此 MSE 對於資料中的 離群值(即誤差特別大的點)非常敏感。一個離群值會對 MSE 產生很大的影響。
相比之下,MAE 計算的是絕對誤差,對離群值的敏感度較低,更能反映模型在大多數樣本上的平均誤差水平。因此,在存在較多離群值的數據中, MAE 可能是一個更穩健的評估指標。
#77
★★
超參數 (Hyperparameter) 與模型參數 (Parameter)
的主要區別是什麼?
答案解析
* 超參數 (Hyperparameter): 這些是在開始訓練過程之前由開發者
手動設定的值,它們控制著學習過程本身。例如:學習率、正則化強度、決策樹的最大深度、KNN 中的 K
值、神經網路的層數和節點數等。超參數的選擇通常需要透過實驗(如使用驗證集)來確定最佳值。
* 參數 (Parameter): 這些是模型 在訓練過程中從資料中自動學習到的內部變數。例如:線性迴歸中的權重和偏置項、神經網路中的權重矩陣等。這些參數是模型知識的體現。
* 參數 (Parameter): 這些是模型 在訓練過程中從資料中自動學習到的內部變數。例如:線性迴歸中的權重和偏置項、神經網路中的權重矩陣等。這些參數是模型知識的體現。
#78
★
樸素貝氏 (Naive Bayes) 分類器是基於哪個數學定理?
答案解析
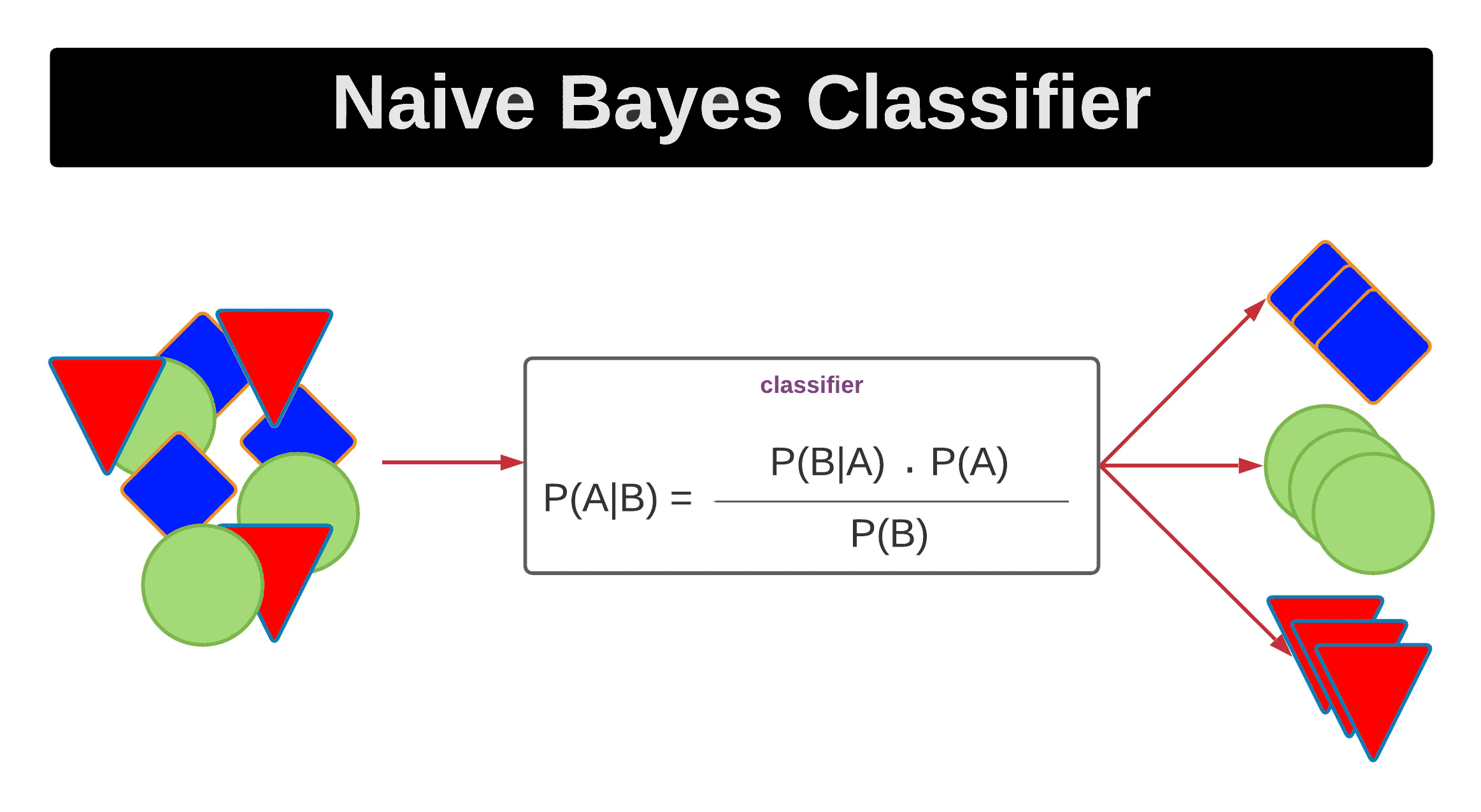
樸素貝氏分類器是一類基於貝氏定理的簡單
機率分類器。它名稱中的「樸素」來自於它做了一個很強的(通常不符合現實,但實用上效果不錯的)假設:即所有
特徵之間都是相互獨立的。儘管這個假設很「天真」,但在許多實際應用中,樸素貝氏分類器表現良好,特別是在文本分類(如垃圾郵件過濾)等領域。
#79
★
在強化學習中,描述代理如何根據當前狀態選擇行動的規則或函數被稱為什麼?
答案解析
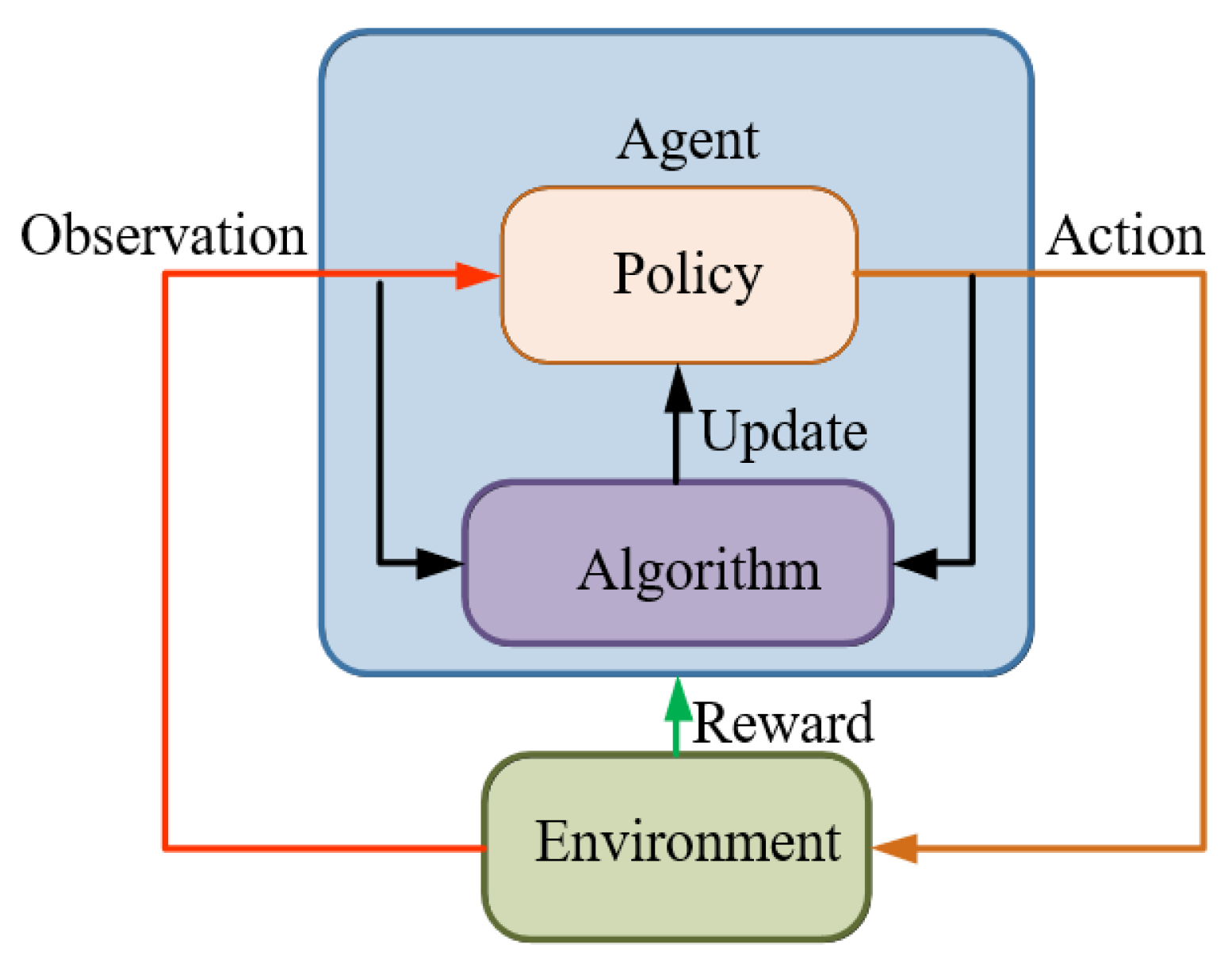
策略 (Policy) 是強化學習的核心組成部分,它定義了
代理的行為方式。具體來說,策略是一個
從狀態到行動的映射
,它告訴代理在給定的環境狀態下應該選擇哪個行動(確定性策略)或者選擇每個行動的機率(隨機性策略)。強化學習的目標就是找到一個最優策略,使得代理能夠獲得最大的累積獎勵。
(A) 獎勵函數定義了行動的好壞。(B) 價值函數評估狀態或狀態-行動對的長期價值。(D) 環境模型描述了環境的動態。
(A) 獎勵函數定義了行動的好壞。(B) 價值函數評估狀態或狀態-行動對的長期價值。(D) 環境模型描述了環境的動態。
#80
★★
為什麼在某些機器學習任務中,需要對資料進行標準化 (Standardization)?
答案解析
標準化(通常指 Z-score 標準化)是一種特徵縮放技術,它將數值特徵轉換為
平均值為 0,標準差為 1 的分佈。這樣做的主要原因是,許多機器學習演算法(如基於梯度下降的、基於距離的)對輸入特徵的
尺度很敏感。如果不同特徵的數值範圍差異很大,範圍大的特徵可能會主導模型的學習過程,即使它本身不一定更重要。標準化可以
消除這種尺度差異,使得所有特徵在模型學習中處於更平等的地位,有助於模型更快地收斂和提高性能。
(A) 是特徵編碼。(C) 是增加資料。(D) 標準化本身不移除離群值,但可能使離群值檢測更容易。
(A) 是特徵編碼。(C) 是增加資料。(D) 標準化本身不移除離群值,但可能使離群值檢測更容易。
#81
★
在K-摺交叉驗證 (K-Fold Cross-validation) 中,參數 K 代表什麼?
答案解析
在K-摺交叉驗證中,參數 K 指的是將原始資料集隨機分割成的互斥子集(或稱為"摺",fold)的
數量。例如,如果 K=5,資料集會被分成 5 個子集。驗證過程會進行 5 次,每次使用其中 4 個子集進行訓練,剩下的 1 個子集進行驗證,確保每個子集都被用作驗證集一次。常用的
K 值包括 5 或 10。
#82
★
過擬合的模型通常具有什麼特點?
答案解析
過擬合的模型表示它過度學習了訓練資料的細節和噪音。
* 因為它很好地擬合了訓練資料,所以它的偏差通常較低(預測值與訓練資料的真實值差異小)。
* 但因為它對訓練資料的特定模式(包括噪音)學習得太好,導致對新資料的泛化能力差,對訓練資料的微小變化很敏感,所以它的 變異數通常較高。
* 因為它很好地擬合了訓練資料,所以它的偏差通常較低(預測值與訓練資料的真實值差異小)。
* 但因為它對訓練資料的特定模式(包括噪音)學習得太好,導致對新資料的泛化能力差,對訓練資料的微小變化很敏感,所以它的 變異數通常較高。
#83
★★★
評估分類模型性能時,AUC (Area Under the Curve) 指的是哪條曲線下的面積?
答案解析
AUC 是 Area Under the Curve 的縮寫,在二元分類模型評估中,它特指
ROC曲線 (Receiver Operating Characteristic Curve) 下方的面積。
ROC 曲線描繪了不同分類閾值下真陽性率 (TPR) 與偽陽性率 (FPR) 的關係。AUC 的值介於 0 和 1 之間,AUC 值越接近 1,表示模型的分類性能越好。AUC = 0.5 表示模型的性能相當於隨機猜測。AUC 提供了一個 不依賴於特定分類閾值的模型整體性能度量。
ROC 曲線描繪了不同分類閾值下真陽性率 (TPR) 與偽陽性率 (FPR) 的關係。AUC 的值介於 0 和 1 之間,AUC 值越接近 1,表示模型的分類性能越好。AUC = 0.5 表示模型的性能相當於隨機猜測。AUC 提供了一個 不依賴於特定分類閾值的模型整體性能度量。
#84
★
機器學習的「學習」過程,本質上是在做什麼?
答案解析
機器學習的「學習」並非簡單的記憶,而是指演算法透過分析大量訓練資料,
自動地發現其中潛在的模式、規律或關係。這個過程通常是透過最佳化一個
目標函數(例如,最小化預測誤差的損失函數)來實現的,演算法會不斷
調整模型內部的參數,使得模型在訓練資料上的表現越來越好(即目標函數值越來越小)。最終目標是讓學到的模式能夠泛化到新的資料上。
#85
★
下列哪個是迴歸 (Regression) 問題的例子?
答案解析
迴歸問題的目標是預測一個連續的數值型輸出。
(B) 房屋的市場售價是一個連續的數值,預測它屬於迴歸問題。
(A) 判斷是否為垃圾郵件是預測兩個類別(是/否),屬於二元分類問題。
(C) 辨識圖片中是否有貓也是預測兩個類別(有/無),屬於二元分類問題。
(D) 將文章分類到不同主題是預測多個類別,屬於多元分類問題。
(B) 房屋的市場售價是一個連續的數值,預測它屬於迴歸問題。
(A) 判斷是否為垃圾郵件是預測兩個類別(是/否),屬於二元分類問題。
(C) 辨識圖片中是否有貓也是預測兩個類別(有/無),屬於二元分類問題。
(D) 將文章分類到不同主題是預測多個類別,屬於多元分類問題。
#86
★
分群 (Clustering) 演算法的目標是什麼?
答案解析
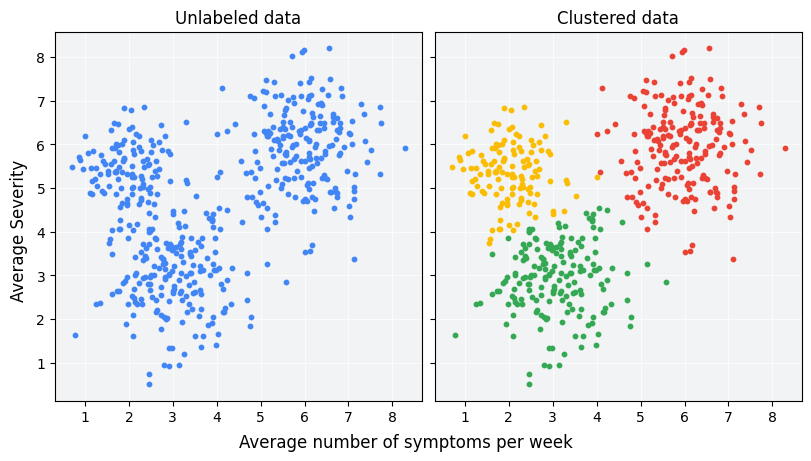
分群是一種非監督式學習任務,其目的是在沒有預先標籤的情況下,根據資料點本身的
特徵和它們之間的相似性(或距離),將資料自動地
劃分成若干個群組(簇)。目標是使得同一個群組內的點彼此盡可能相似,而不同群組之間的點盡可能不同。
#87
★
在監督式學習中,標籤 (Label) 指的是什麼?
答案解析
在監督式學習中,訓練資料包含輸入特徵和對應的輸出標籤。
標籤就是我們希望模型學習預測的目標,也就是每個輸入樣本對應的
正確答案。例如,在垃圾郵件分類中,標籤是「垃圾郵件」或「非垃圾郵件」;在房價預測中,標籤是房屋的實際價格。
#88
★
驗證集 (Validation Set) 的資料應該來自哪裡?
答案解析
為了客觀地評估模型在訓練過程中的表現並有效地調整超參數,驗證集必須是
獨立於訓練集的資料。也就是說,用於驗證模型的資料不能是模型在訓練時已經「看過」的資料。同時,為了最終能夠在
測試集上得到無偏的泛化性能評估,驗證集也必須
獨立於測試集。因此,標準做法是將原始資料集劃分成三個互不重疊的部分:訓練集、驗證集和測試集。
#89
★
哪種情況下,模型可能更容易發生過擬合?
答案解析
過擬合發生在模型學習了過多訓練資料的細節和噪音時。模型越複雜(例如:參數越多、決策樹深度越深、神經網路層數越多),它
擬合訓練資料的能力就越強,也就越有可能捕捉到訓練資料中的噪音,從而導致過擬合。
(A) 簡單模型更容易欠擬合。(C) 更多訓練資料通常有助於防止過擬合。(D) 強正則化是防止過擬合的方法。
(A) 簡單模型更容易欠擬合。(C) 更多訓練資料通常有助於防止過擬合。(D) 強正則化是防止過擬合的方法。
#90
★
評估機器學習模型性能的最終目的是什麼?
答案解析
評估機器學習模型性能的根本目的,不是看它在已經學習過的訓練集上表現如何,而是要預估它在
未來實際應用中遇到新的、未曾見過的資料時,其表現會有多好(即
泛化能力)。這是因為我們最終是希望模型能夠解決真實世界的問題,而不是僅僅擬合過去的數據。使用獨立的
測試集進行評估就是為了模擬這種真實應用場景。
#91
★★
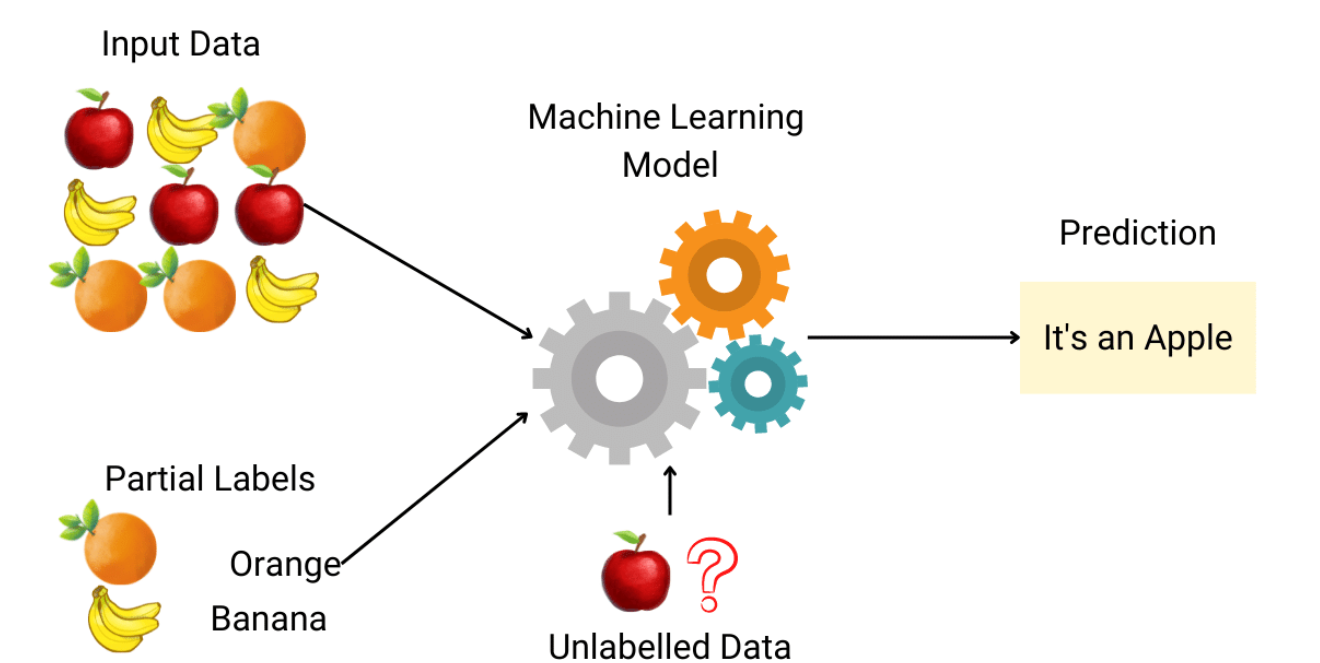
半監督式學習 (Semi-supervised Learning) 結合了哪兩種學習方式的特點?
答案解析
半監督式學習是一種介於監督式學習和非監督式學習之間的學習範式。它通常使用
少量帶有標籤的資料和
大量未標記的資料進行訓練。其目標是利用未標記資料中包含的資訊來輔助學習過程,以期獲得比僅使用少量標籤資料的監督式學習更好的性能,同時避免了對大量標籤資料的需求。
#92
★★
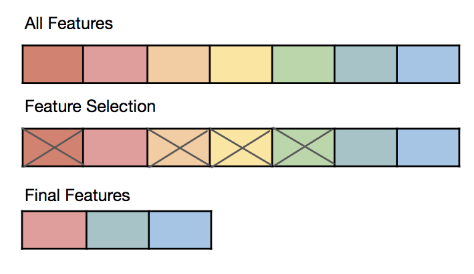
為什麼在訓練模型前,有時需要進行特徵選擇 (Feature Selection)?
答案解析
特徵選擇是從原始特徵集合中挑選出一個子集的過程。其主要目的包括:
* 簡化模型:減少輸入特徵的數量,使模型更易於理解和解釋。
* 縮短訓練時間:處理更少的特徵通常更快。
* 避免維度災難:在高維度空間中,資料點可能變得稀疏,影響模型性能。
* 提高泛化能力:移除不相關或冗餘的特徵可以減少噪音干擾,有助於防止過擬合,提高模型在新資料上的表現。
(A) 目的是簡化。(C) 是特徵編碼。(D) 是特徵縮放。
* 簡化模型:減少輸入特徵的數量,使模型更易於理解和解釋。
* 縮短訓練時間:處理更少的特徵通常更快。
* 避免維度災難:在高維度空間中,資料點可能變得稀疏,影響模型性能。
* 提高泛化能力:移除不相關或冗餘的特徵可以減少噪音干擾,有助於防止過擬合,提高模型在新資料上的表現。
(A) 目的是簡化。(C) 是特徵編碼。(D) 是特徵縮放。
#93
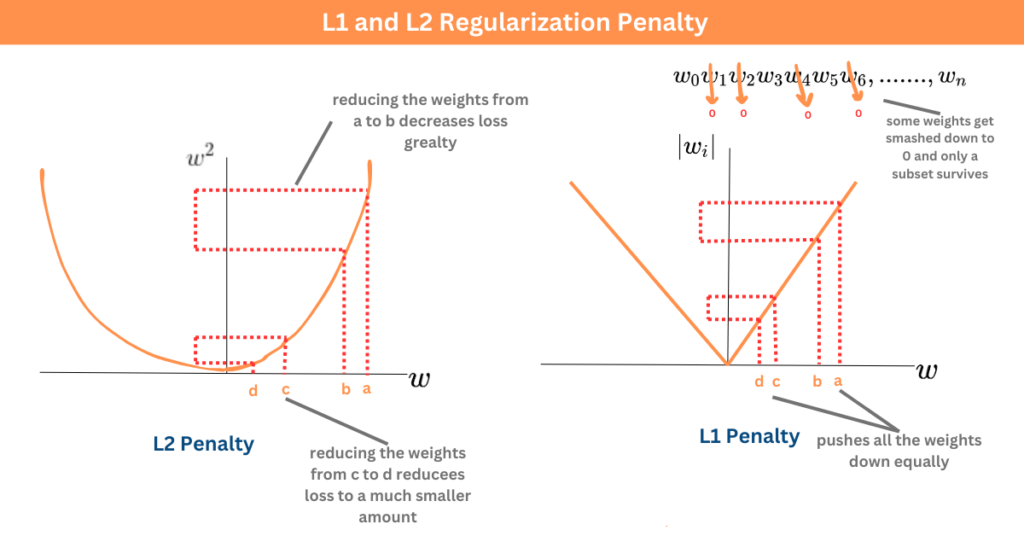
★★
L1 和 L2 正則化的主要區別在於它們如何懲罰模型的參數(權重)?
答案解析
L1 和 L2 正則化都是在損失函數中加入懲罰項來限制模型複雜性,但懲罰方式不同:
* L1 正則化 (Lasso Regression): 懲罰項是模型權重絕對值之和(λΣ|wᵢ|)。它傾向於將一些不重要的特徵的權重 縮減到恰好為零,從而產生稀疏的模型,具有內建的特徵選擇效果。
* L2 正則化 (Ridge Regression): 懲罰項是模型權重平方和(λΣwᵢ²)。它傾向於使所有權重都 變小但通常不為零,使得權重分佈更平滑。
兩者都能有效防止過擬合,但 L1 因其稀疏性也可用於特徵選擇。
* L1 正則化 (Lasso Regression): 懲罰項是模型權重絕對值之和(λΣ|wᵢ|)。它傾向於將一些不重要的特徵的權重 縮減到恰好為零,從而產生稀疏的模型,具有內建的特徵選擇效果。
* L2 正則化 (Ridge Regression): 懲罰項是模型權重平方和(λΣwᵢ²)。它傾向於使所有權重都 變小但通常不為零,使得權重分佈更平滑。
兩者都能有效防止過擬合,但 L1 因其稀疏性也可用於特徵選擇。
#94
★★
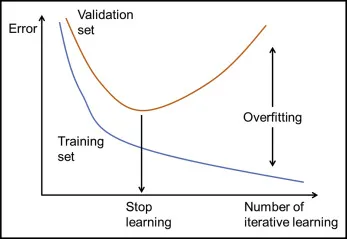
在模型評估中,學習曲線 (Learning Curve) 通常用來視覺化什麼?
答案解析
學習曲線是一種診斷機器學習模型行為的工具。它通常繪製兩條曲線:
1. 模型在訓練集上的性能(例如:訓練誤差)。
2. 模型在驗證集上的性能(例如:驗證誤差)。
橫軸通常是訓練樣本的數量或訓練的迭代次數。
通過觀察這兩條曲線的形狀和它們之間的差距,可以幫助判斷模型是否存在高偏差(欠擬合,兩條曲線都表現差且可能收斂)或 高變異數(過擬合,訓練曲線表現好,驗證曲線表現差,兩者差距大),並指導下一步的改進方向(例如:獲取更多資料、調整模型複雜度等)。
1. 模型在訓練集上的性能(例如:訓練誤差)。
2. 模型在驗證集上的性能(例如:驗證誤差)。
橫軸通常是訓練樣本的數量或訓練的迭代次數。
通過觀察這兩條曲線的形狀和它們之間的差距,可以幫助判斷模型是否存在高偏差(欠擬合,兩條曲線都表現差且可能收斂)或 高變異數(過擬合,訓練曲線表現好,驗證曲線表現差,兩者差距大),並指導下一步的改進方向(例如:獲取更多資料、調整模型複雜度等)。
#95
★
機器學習的目標是讓機器?
答案解析
機器學習的核心思想是賦予機器
從資料中學習的能力,而不是僅僅依賴預先編寫的固定指令。通過分析經驗數據,機器學習模型能夠識別模式、做出預測或決策,並隨著接觸更多數據而
不斷改進其性能。目標是讓機器在特定的任務上表現得更好,更有效率。
(A) 目標是輔助或自動化,不一定是完全取代。(B) 目前的機器學習還不具備真正的情感思考能力。(D) 目前的 AI 還遠未達到與人類完全相同的通用智慧水平。
(A) 目標是輔助或自動化,不一定是完全取代。(B) 目前的機器學習還不具備真正的情感思考能力。(D) 目前的 AI 還遠未達到與人類完全相同的通用智慧水平。
#96
★
監督式學習中的「監督」指的是什麼?
答案解析
在監督式學習中,「監督」的比喻來自於訓練資料中存在的「正確答案」或「標籤」。這些標籤就像一位老師(監督者),在模型學習過程中
提供指導,告訴模型對於給定的輸入,正確的輸出應該是什麼。模型透過比較自己的預測和這些「老師」給出的答案來學習和修正錯誤。
#97
★
下列哪個場景最適合使用非監督式學習?
答案解析
非監督式學習的核心在於探索未標記資料中的內在結構和模式。
(C) 探索大量客戶資料以找出未知的客戶群體(客戶細分),目的是發現資料中自然形成的群組,而事先並不知道這些群體是什麼或有多少個,這是典型的 分群任務,屬於非監督式學習。
(A) 預測股價是迴歸問題(監督式)。
(B) 判斷交易是否詐欺是分類問題(通常是監督式,需要標記好的詐欺/非詐欺樣本,儘管異常檢測有時也用非監督方法)。
(D) 預測疾病是分類問題(監督式)。
(C) 探索大量客戶資料以找出未知的客戶群體(客戶細分),目的是發現資料中自然形成的群組,而事先並不知道這些群體是什麼或有多少個,這是典型的 分群任務,屬於非監督式學習。
(A) 預測股價是迴歸問題(監督式)。
(B) 判斷交易是否詐欺是分類問題(通常是監督式,需要標記好的詐欺/非詐欺樣本,儘管異常檢測有時也用非監督方法)。
(D) 預測疾病是分類問題(監督式)。
#98
★
強化學習中的「環境 (Environment)」通常指的是什麼?
答案解析
在強化學習的框架中,環境是代理所處的、與之互動的外部世界或系統。代理透過
觀察環境的狀態 (State),
執行行動 (Action),然後從環境中接收到一個獎勵 (
Reward) 和一個新的狀態。環境定義了遊戲規則、物理定律或系統動態。
(A) 代理是學習者。(C) 策略是代理的行為規則。(D) 獎勵是環境的回饋。
(A) 代理是學習者。(C) 策略是代理的行為規則。(D) 獎勵是環境的回饋。
#99
★
下列何者是機器學習模型訓練前不需要的步驟?
答案解析
模型訓練前的準備工作主要集中在資料上。
(A) 需要先收集相關資料。
(B) 需要對收集到的原始資料進行清理、轉換等預處理。
(C) 可能需要選擇重要的特徵或創建新的特徵。
(D) 模型部署是模型訓練完成並評估滿意後,將其應用到實際環境中的步驟,是在訓練 之後進行的。
(A) 需要先收集相關資料。
(B) 需要對收集到的原始資料進行清理、轉換等預處理。
(C) 可能需要選擇重要的特徵或創建新的特徵。
(D) 模型部署是模型訓練完成並評估滿意後,將其應用到實際環境中的步驟,是在訓練 之後進行的。
#100
★
如果一個分類模型的準確率 (Accuracy) 很高,是否就一定代表這個模型是好的?
答案解析
高準確率不一定代表模型就是好的。特別是在資料類別不平衡的情況下,例如,如果一個資料集中 99% 的樣本屬於 A 類,1% 屬於 B
類,那麼一個簡單地將所有樣本都預測為 A 類的「愚蠢」模型也能達到 99% 的準確率,但它對於識別 B 類樣本完全沒有能力。
因此,評估模型時不能只看準確率,還需要根據具體問題考慮精確率、召回率、F1分數、 AUC等其他指標,並結合業務需求來判斷模型的好壞。
因此,評估模型時不能只看準確率,還需要根據具體問題考慮精確率、召回率、F1分數、 AUC等其他指標,並結合業務需求來判斷模型的好壞。